Escalonamento
Unix È time-sharing, ilus„o de m˙ltiplos processos concorrentes:
- EstratÈgia (Policy): regras usadas para decidir que
processo colocar e quando mudar;
- ImplementaÁ„o: estruturas de dados e algoritmos usados na
implementaÁ„o do sistema
Objectivos conflituantes:
- Resposta r·pida para processos interactivos;
- throughput alto para processos background;
- evitar "starvation"
ImplementaÁ„o exige context switch, uma operaÁ„o cara.
- Guardar registos correntes no PCB;
- Ler PCB do novo registo corrente;
- Tarefas especÌficas da arquitectura:
- Flush de caches de dados, instruÁıes, ou TLB;
- Prejudica o pipeline e reduz localidade.
- Tb fazer flush do pipeline.
- Custos influenciam escolha da melhor estratÈgia.
Ver __switch_to em arch/i386/process.c e
kernel/sched.c para Linux. Ver cpu_switch em
i386/i386/swtch.s para FreeBSD.
OS interrompido HZ ticks por segundo:
- reiniciar hw clock, se necess·rio.
- incrementar estatÌsticas.
- escalonamento, eg. prioridades e time-slice.
- enviar SIGXCPU para processo se excedeu quota.
- alterar relÛgio de tempo real.
- processar callouts
- acordar processos de sistemas como swapper e
pageout
- processar alarmes.
Algumas tarefas sÛ s„o processadas no major tick.
Em Linux do_timer_interrupt()
(arch/i386/kernel/time.c) ->
do_timer() (kernel/timer.c) ->
mark_bh() (include/kernel/interrupt.h)
-> tasklet_action()
(kernel/softirq.c)
FunÁıes a chamar mais tarde (timeout ou task queue):
- Retransmiss„o de pacotes;
- FunÁıes do escalonador e gestor de memÛria;
- MonitoraÁ„o de devices;
- Polling
Interrupt handler coloca uma flag que È verificada no retorno ý prioridade
normal.
Callouts s„o ordenados por:
- "tempo atÈ disparar" em BSD;
- ringlist em Linux: ver run_timer_list() em
kernel/timer.c.
Alarmes s„o activados ao fim de um certo intervalo de tempo:
- Tempo-Real, SIGALRM
- profiling, SIGPROF
- virtual-time, SIGVTALRM
- BSD usa setitimer(), microsegundos, mas funciona em
ticks.
- SVR4 fornece hrtsys().
- POSIX fornece nanosleep() com precis„o de nano-segundos.
- Note que processo sÛ responde ao sinal quando È escalonado, o
que afecta precis„o.
Ver kernel/timer.c e kernel/itimer.c em Linux.
TrÍs tipos de aplicaÁıes: interactivas, batch e real-time.
- Unix tradicional desenhado para aplicaÁıes interactivas.
- Cada processo tem uma prioridade que varia din‚mincamente.
- Processos de mais alta prioridade tiram outros processos do CPU
mesmo quando o processo n„o terminou o seu quantum.
- Kernel È non-preemtible: processo sÛ returna o CPU quando
bloqueia ou quando regressa a User Mode.
- Prioridades: 0 a 49 para kernel, 50 a 127 para
user-mode.
- Em proc: p_pri, prioridade corrente;
p_usrpri, prioridade em modo utilizador, p_cpu,
uso de CPU, e p_nice.
- Depois de bloquear, pri È associada ý prioridade do
recurso (eg., 28 para terminais e 20 para disco).
- quando regressa a user mode, volta a usrpri.
- nice pode ser usado para controlar prioridades.
- p_usrpri = PUSER + (p_cpu/4) +
(2×p_nice)
- p_cpu decai por um factor de 1/2 em SVR3 e (2×load_average)/(2×load_average+1) em BSD,
activado de segundo a segundo por um callout.
load_average È o n˙mero mÈdio de processos execut·veis
no ˙ltimo segundo.
- BSD previne "starvation": factor dependente do load evita que
prioridades aumentem quando a load aumenta.

- s„o mantidas 32 filas com as prioridades (VAX). whichqs
contÈm um bitmask com um 1 para filas ocupadas.
- swtch() examina primeira fila, muda contexto, e quando
retorna processo j· est· executando.
- Cada 100 ms (BSD) roundrobin() vai buscar outro processo com
a mesma prioridade. Sen„o, o mesmo processo continua.
- schedcpu() È chamada de segundo a segundo para recomputar a
prioridade.
- clock recomputa prioridade do processo corrente cada vez em 4.
- flag runrun È usada para indicar que processo de mais alta
prioridade est· ý espera de ser executada, e È verificada antes de entrar
em user-mode.
Problemas do Escalonador BSD:
- N„o escala bem: muitos processos faz com que recomputar prioridades
seja pesado.
- N„o se pode dar uma porÁ„o de CPU a um processo.
- N„o h· garantias de tempo de resposta para aplicaÁıes em tempo
real.
- AplicaÁıes n„o podem controlar as suas prioridades.
- Kernel nonpreemptive significa que processos de prioridade alta podem
ter que esperar muito tempo antes de executar.
Objectivos do desenho do escalonador em SVR4:
- Suportar mais aplicaÁıes, incluindo tempo-real.
- Separar a polÌtica de escalonamento dos mecanismos de
escalonamento.
- Permitir ýs aplicaÁıes maior controle sobre prioridade e
escalonamento.
- Definir uma interface bem estabelecida.
- Permitir a adiÁ„o de novas polÌticas de uma forma modular.
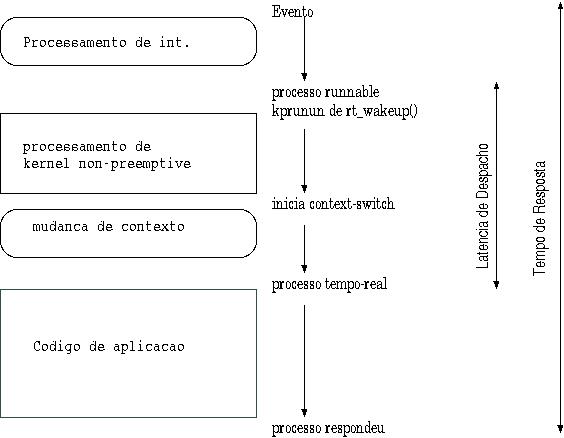
- Limitar a latÍncia de despacho para aplicaÁıes dependentes do
tempo.
Ideias principais:
- Fornecidas duas classes: time-sharing e tempo-real.
- Processamento independentes de classe para:
- mudanÁa de contexto;
- manipulaÁ„o da fila de processos;
- "preemption".
- Interface para funÁıes com heranÁa e prioridades.
O nÌvel independente de classe tem as seguintes caracterÌsticas:
- Prioridades de 0 a 160, com filas separadas.
- Processo de maior prioridade corre sempre.
- Processos s„o colocados na fila por setfrontdq() e
setbackdq() e removidas por dispdeq().
- Para evitar latÍncia de despacho (problema em Unix por o kernel
ser nonpreemptive) define "preemption points".
- Nesses pontos kernel testa kprunrun para ver se h·
processo tempo-real e tira o processo corrente.
- Exemplos s„o em parsing do pathname; rotina open()
antes de criar o ficheiro; e antes de libertar p·gina.
- runrun existe: preempt() chama
CL_PREEMPT() e depois swtch().
A componente dependente de classe È acedida como um vector de funÁıes que
implementam as componentes dependentes de classe.
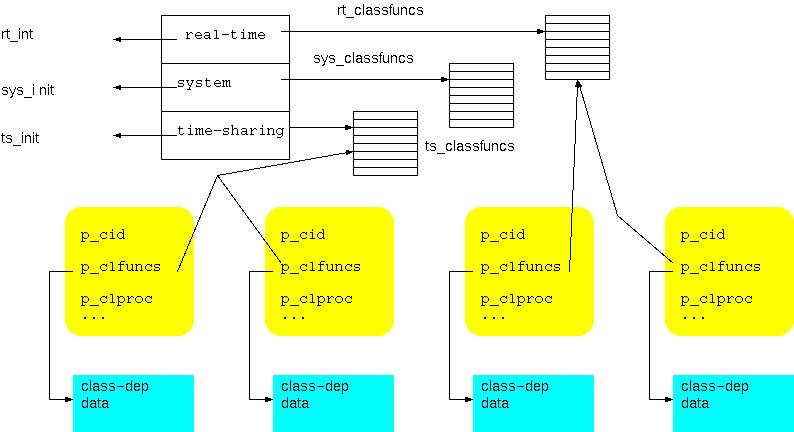
- Processos herdam classe do pai e podem ser mudados de classe com
priocntl()
- proc inclui ptrs. para id da classe,
funÁıes da classe, e estruturas de dados privadas.
- CL_TICK È chamada do relÛgio: time slice, recomputa
prio, expiraÁ„o do quantum.
- CL_FORK inicializa. CL_FORKRET inicializa
runrun permitindo ao filho correr primeiro.
- CL_ENTERCLASS e CL_EXITCLASS s„o chamadas
ao entrar e sair de classe.
- CL_SLEEP de sleep() e pode recomputar prioridade.
- CL_WAKEUP È chamada de wakeprocs() coloca
processo na fila e pode colocar runrun ou
kprunrun.
Prioridades s„o divididas entre:
- 0-59 para time-sharing;
- 60-99 para system;
- 100-159 para tempo-real.
Escalonamento È "round-robin" usando uma tabela de par‚metros fixa:
- Processos com menor prioridade tÍm maior time slice.
- Usa event-driven scheduling: prioridade È alterada na resposta
a events.
- Dados dependentes de classe:
- ts_timeleft: tempo para
terminar o quantum;
- ts_cpupri, a parte de sistema;
- ts_upri, parte de usu·rio (nice);
- ts_umdpri: prioridade em modo user È
max(0,min(59,ts_cpupri+ts_upri)),
- ts_dispwait: tempo de relÛgio desde o inÌcio do quantum.
- Em modo kernel prioriade È determinada pela condiÁ„o de sleep,
depois È restaurada de ts_umdpri.
|
| glbpri | quant | tqexp |
slpret | mxwt | lwait |
|
0 | 0 | 100 | 0 | 10 | 5 | 10 |
|
1 | 1 | 100 | 0 | 11 | 5 | 10 |
|
... | ... | ... | ... | ... | ... | ... |
|
15 | 15 | 80 | 7 | 25 | 5 | 25 |
|
... | ... | ... | ... | ... | ... | ... |
|
40 | 40 | 20 | 30 | 50 | 5 | 50 |
|
... | ... | ... | ... | ... | ... | ... |
|
59 | 59 | 10 | 49 | 59 | 5 | 59 |
|
|
- ts_globpri: prioridade global;
- ts_quantum: quantum;
- ts_tqexp: ts_cpupri depois
de quantum;
- ts_tqexp: ts_cpupri depois de sleep;
- ts_maxwait: n˙mero de segundos para esperar fim de
quantum antes de usar ts_lwait.
- Exigem tempo de latÍncia e tempo de resposta
limitadas.
- prioridade maior do que processos em modo kernel.
- Escalonamento com prioridade e quantum fixos.
Novo algoritmo de escalonamento:
- Configur·vel por uma tabela.
- N„o È preciso recomputar prioridades de todos os processos uma
vez por segundo.
- Ajustes podem ser necess·rios para manter equilibrio e evitar
prejudicar processos interactivos com computaÁ„o.
- Obj: definir uma nova classe sem mexer no cÛdigo do
kernel.
- priocntl() È restrito ao superuser.
- real-time n„o È deadline-driven.
- DifÌcil encontrar prioridades certas
(Nieh): escrita,
batch, video e X. Necess·rio colocar video e X como tempo-real, mas
prejudicava batch-jobs e sistema n„o respondia ao rato
Solaris tem um mecanismo de escalonamento diferente:
- Kernel È "preemptive".
- Threads de interrupt permitem evitar ipl
- Suporte a multiprocessamento.
- Evitar escalonamento escondido
- HeranÁa de prioridades
- Turnstiles.
Suporte a Multiprocessadores inclui:
- ⁄nica fila de despacho.
- Threads podem ser restritos a um processador.
- Processadores podem enviar cross-processor interrupts.
- Cada processador mantÈm:
- cpu_thread executando;
- cpu_dispthread, o ˙ltimo thread executado;
- cpu_idle thread;
- cpu_runrun, cpu_kprunun;
cpu_chosen_level, prioridade do thread que vai tomar o
processador.
- Se Pi tem um processo com maior prioridade que Pj, coloca o
seu chosen_level e envia um IPI para Pj.

T6 e T7 acordam:

Garante que T7 fica na fila, mesmo que outro CPU veja que P3
est· a correr com prioridade 100.
O kernel faz trabalho assÌncrono, sem considerar a prioridade das
threads que fizeram a chamada original:
- Kernel pode verificar pedidos em STREAMS, que s„o servidos pelo
e com a prioridade do processo actual em modo kernel. Ideia: STREAMs
È feito em modo kernel, e abaixo de tempo real.
- Problema: pedidos de STREAMs feitos por processos de tempo-real?
- Callouts tÍm o mesmo problema, por principio s„o executados
com prioridade de interrupts.
- Solaris usa uma callout thread, que n„o inclui os
callouts de real-time.
Thread de baixa prioridade pode ser necess·rio para activar thread de alta
prioridade:

Quando T3 acorda:

SoluÁ„o correcta:

O problema pode ser recursivo!
- HeranÁa de prioridade: threads tÍm prioridade global,
dependendo da classe, e prioridade herdada que depende da
interacÁ„o com objectos de sincronizaÁ„o.
- pi_willto() È usada quando thread bloqueia para
passear prioridade recursivamente para os donos de um objecto.
- F·cil para mutexes.
- Em geral impossÌvel para sem·foros e vari·veis de
sincronizaÁ„o.
- readers-writers: Solaris usa owner-of-record, primeiro
thread a ler o objecto.
- HeranÁa de prioridades reduz tempo de espera, mas n„o garante
TR, nem evita que cadeias de bloqueamento cresÁam.
Muitos objectos de sincronizaÁ„o podem exigir muitos recursos ao sistema.
- Kernel tradicional usa "sleep channel", um endereÁo, e
usa esse endereÁo para procurar numa tabela de hash.
- Turnstiles s„o objectos de tamanho fixo que mantem os
dados para sinc., como um ptr para a lista de threads bloqueados e
para o dono.
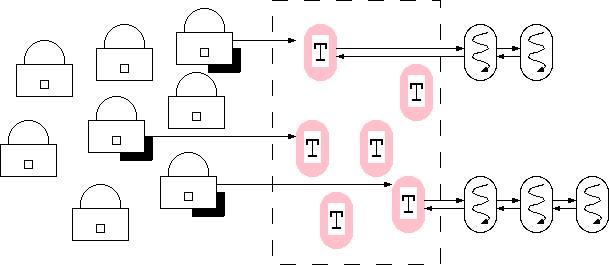
- Threads bloqueados s„o colocados em ordem de prioridade e
acordados por signal() ou broadcast()
- Mach escalona threads independentemente de tasks:
- Ignora overhead de context switches.
- Prioridade-base por task + factor de uso por thread, decaindo a
5/8 por segundo inactivo.
- C·lculos s„o feitos pelo thread qdo acorda, e pelo relÛgio. Um
thread interno recomputa prioridades de 2 em 2 segundos.
- Um thread corre atÈ ao fim do quantum. Cede CPU com thread de > prio.
- handoff scheduling: thread pode passar controle a
outro:
- Mach n„o usa IPIs: atraso prejudica RT, n„o time-sharing.
- Utilizadores podem criar conjuntos de processadores. Um
servidor determina a alocaÁ„o.
- Threads podem ser forÁados a correr num CPU: ˙til para
servidores sequenciais, ie de UNIX.
- … possÌvel dedicar um conjunto de CPUs a uma task: gang
scheduling.
- ˙til para barreiras pq nenhum thread se atrasa;
- e aplicaÁ„oes fine-grained, pq podem atrasar num thread
suspenso.
- Cada CPU tem uma fila local, e existe fila para o conjunto de trabalho.
- Filas locais s„o vistas primeiro.
- sched_setscheduler: time-sharing, round-robin (prio.
fixa) e FIFO (prio fixa, sem time-quantum).
- Escalonador escolhe o processo com > prioridade. Se
processador preempted antes de terminar o quantum, colocado na
frente da fila, sen„o atr·s.
- Prioridades de threads s„o sobrepostas, dando flexibilidade:
- Time-sharing entre 0 e 29.
- M·ximo È 63.
- Para ir acima de 19 processo precisa de superuser.
- sched_setparam muda prioridades de processo FIFO e
round-robin;
- sched_yield cede o resto do quantum para outro
processo com a mesma prio.
- Objectivos:
- optimizar mudanÁas de contexto;
- optimizar utilizaÁ„o de cache;
- evitar problemas de luta por recursos quando v·rios processos
s„o acordados da mesma fila global.
- Cada CPU tem uma fila local, e existe fila global.
- Escalonador tenta manter as filas equilibradas.
- Tenta recolocar threads no mesmo processador: soft
affinity. Time-sharing threads usam filas locais a CPU. Sistema
evita load imbalance.
- Processos com prio. fixa s„o escalonados de fila global,
escalonador tenta reutilizar CPU.
Implementado por schedule() em kernel/sched.c:
- Classes de escalonamento semelhantes a True64 Unix.
- Usa goodness() para estimar em que ponto o processo precisa
do CPU:
- em YIELD, retorna -1;
- RT ou FIFO: retorna 1000+rt_priority;
- OTHER: se p -> counter =
0, d· 0;
- comeÁa com p -> counter;
- d· +PROC_CHANGE_PENALTY se tiver corrido no mesmo CPU (15
no x86);
- d· +1 se tiver mesmo mm;
- d· +20 e subtrai p -> nice.
- schedule() percorre a lista dos processos activos e
escolhe aquele com maior goodness.
- p -> counter È ajustado em:
- se nenhum processo escalon·vel tiver quanta, usando
p -> nice.
- timer decrementa p -> counter e se 0
coloca p -> need_resched a 1
(update_process_times()).
- pai divide com filho em fork();
- pai recupera p -> counter do filho
em exit();
- processo de tempo-real forÁa recomputaÁ„o se tiver
interrompido processo time-sharing p com
p -> counter == 0.
- wake_up_process(): processos que acordam podem forÁar
reescalonamento se tiverem maior goodness que processo no CPU
currente; complexo em SMP.
- Linux pode definir interfaces em source: aumenta eficiÍncia
- Problemas:
- Suportar a multithreads, ver trabalho da IBM para
Java
e Linux Scalability
Project?
- Afinidade?
- Hints da AplicaÁ„o?
- Colocar CPUs ofline?
- Fair-share: cada "share" tem uma percentagem do CPU e outros
recursos, eg Eclipse.
- Deadline Driven com v·rios tipos de deadline:
- Hard s„o garantidas;
- Soft tem probabilidade quantificada;
- Time-Sharing e batch.
- 3-niveis com isocronico,
tempo-real e time-sharing:
- reserva de recursos: CPU, MEM, HD;
- processos de tempo-real podem ser interrompidas por tarefas
isocronicas em pontos bem-definidos (fecho de unidade de trabalho)
- tarefas isocronicas usam escalonamento "rate-monotonic".
- Tarefas time-sharing s„o fully preemptible.
- Evita receive livelock onde sistema sÛ processa
ints colocando rede como TR.
vitor@cos.ufrj.br


