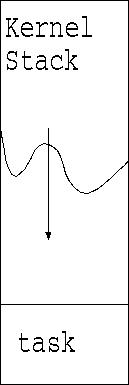
Processos e Threads
- Em Unix, um processo executa em 2 modos:
- Cada processo tem memória virtual:
- kernel ou system space: partilhada por todos os processos.
- memória privada: (pilha, bss).
- memória partilhada: código, bibliotecas partilhadas,
mmap
- Privadas mas controladas pelo kernel: área-u e
pilha do kernel.
- Funçőes do Kernel podem executar no contexto:
- Processo (ie, syscall): kernel pode bloquear.
- Kernel, ou interrupt: năo pode bloquear.
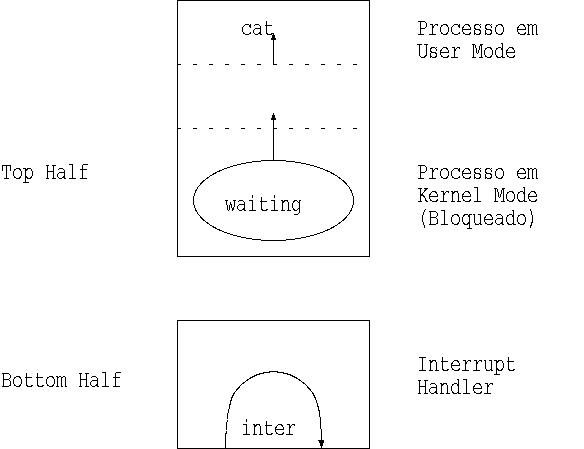
- Top-half e bottom-half do kernel.
- Espaço de Endereçamento do Usuário:
- texto;
- dados;
- pilha do usuário;
- memória partilhada.
- Informaçăo de controle: área-u; proc; pilha
modo-kernel; mapa de traduçăo de endereços.
- Credenciais: UIDs, GIDs.
- Variáveis de Ambiente
- Contexto HW: PC, SP, PSW (processor status word), mmem regs, FPU
regs.
- UID/GID real e efectiva.
- Efectiva: usada para abrir ficheiros.
- Real: usada para enviar sinais.
- programs em suid mode: mudam UID efectivo.
- programs em sgid mode: mudam GID efectivo.
- setuid() ou setgid(): permitem voltar ao ID real.
- SYSV mantém saved UID e GID que sao restaurados por setuid.
- BSD suporta vários grupos por utilizador.
- PCB (process control block): armazena o contexto HW quando o processo
năo está activo.
- pointer to proc;
- UID e GID real e efectivo;
- argumentos e resultado da syscall corrente;
- signal handlers;
- info sobre texto, dados e pilha, mais gestăo de memória;
- FD abertos (dinâmico ou estático);
- nó-v do directório currente e do terminal currentel
- estatísticas (CPU, profiling, quota);
- Pilha modo-kernel.
- PID e SID (id da sessăo).
- endereço da área u no kernel.
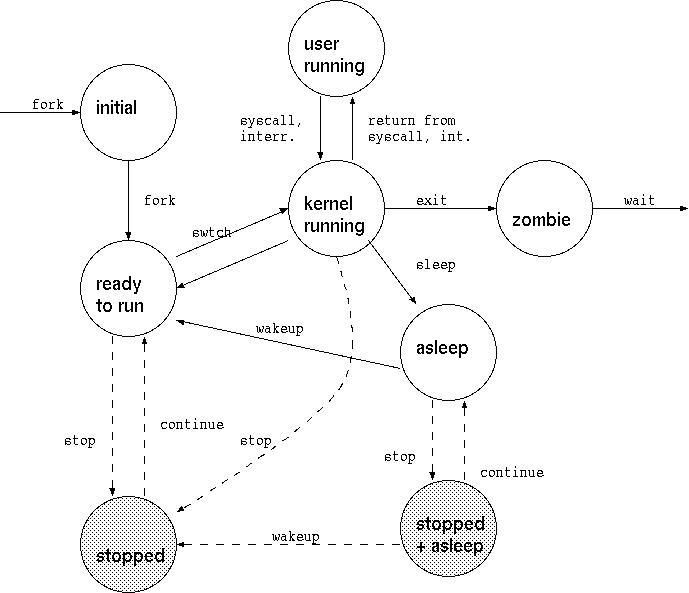
- estado do processo.
- ptrs para incluir o processo numa fila de escalonamento ou de "sleep".
- "sleep channel" para processos bloqueados.
- prioridade de escalonamento.
- sinais que săo aceites pelo processo.
- gestăo de memória.
- ptr. para lista de processos activos, livres ou zombie.
- Ptrs. para hierarquia de processos e para hash queue on PID.
- Flags Misc.
Em /usr/src/linux/include/kernel/sched.h
struct task_struct {
/*
* offsets of these are hardcoded
* elsewhere - touch with care
*/
/* -1 unrunnable, 0 runnable, >0 stopped*/
volatile long state;
/* per process flags, defined below */
unsigned long flags;
int sigpending;
/* thread address space:
0-0xBFFFFFFF for user-thead
0-0xFFFFFFFF for kernel-thread
*/
mm_segment_t addr_limit;
struct exec_domain *exec_domain;
volatile long need_resched;
unsigned long ptrace;
/* Lock depth */
int lock_depth;
/*
* offset 32 begins here on 32-bit platforms.
* We keep all fields in a single cacheline
* that are needed for
* the goodness() loop in schedule().
*/
long counter;
long nice;
unsigned long policy;
struct mm_struct *mm;
int has_cpu, processor;
unsigned long cpus_allowed;
/*
* (only the 'next' pointer fits
* into the cacheline, but
* that's just fine.)
*/
struct list_head run_list;
unsigned long sleep_time;
struct task_struct *next_task,
*prev_task;
struct mm_struct *active_mm;
/* task state */
struct linux_binfmt *binfmt;
int exit_code, exit_signal;
/* The signal sent when the parent dies */
int pdeath_signal;
/* ??? */
unsigned long personality;
int dumpable:1;
int did_exec:1;
pid_t pid;
pid_t pgrp;
pid_t tty_old_pgrp;
pid_t session;
pid_t tgid;
/* boolean value for session group leader */
int leader;
/*
* pointers to (original) parent process,
* youngest child, younger sibling,
* older sibling, respectively.
* (p->father can be replaced with
* p->p_pptr->pid)
*/
struct task_struct *p_opptr, *p_pptr,
*p_cptr, *p_ysptr,
*p_osptr;
struct list_head thread_group;
/* PID hash table linkage. */
struct task_struct *pidhash_next;
struct task_struct **pidhash_pprev;
/* for wait4() */
wait_queue_head_t wait_chldexit;
/* for vfork() */
struct semaphore *vfork_sem;
unsigned long rt_priority;
unsigned long it_real_value,
it_prof_value, it_virt_value;
unsigned long it_real_incr,
it_prof_incr, it_virt_incr;
struct timer_list real_timer;
struct tms times;
unsigned long start_time;
long per_cpu_utime[NR_CPUS],
per_cpu_stime[NR_CPUS];
/* mm fault and swap info: this can arguably
be seen as either mm-specific or
thread-specific */
unsigned long min_flt, maj_flt, nswap,
cmin_flt, cmaj_flt, cnswap;
int swappable:1;
/* process credentials */
uid_t uid,euid,suid,fsuid;
gid_t gid,egid,sgid,fsgid;
int ngroups;
gid_t groups[NGROUPS];
kernel_cap_t cap_effective,
cap_inheritable, cap_permitted;
int keep_capabilities:1;
struct user_struct *user;
/* limits */
struct rlimit rlim[RLIM_NLIMITS];
unsigned short used_math;
char comm[16];
/* file system info */
int link_count;
/* NULL if no tty */
struct tty_struct *tty;
/* How many file locks are being held */
unsigned int locks;
/* ipc stuff */
struct sem_undo *semundo;
struct sem_queue *semsleeping;
/* CPU-specific state of this task */
struct thread_struct thread;
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
/* signal handlers */
/* Protects signal and blocked */
spinlock_t sigmask_lock;
struct signal_struct *sig;
sigset_t blocked;
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
int (*notifier)(void *priv);
void *notifier_data;
sigset_t *notifier_mask;
/* Thread group tracking */
u32 parent_exec_id;
u32 self_exec_id;
/* Protection of (de-)allocation:
mm, files, fs, tty */
spinlock_t alloc_lock;
};
- syscall:
Um wrapper chama a instruçăo chmk no VAX, syscall
no MIPS, trap no MC68k, LCALL ou int no
x86,....
syscall() no kernel copia arguments e salta através da
tabela sysent (sys_call_table em Linux).
No retorno copia valores de retorno em registo, restaura contexto
HW, e regressa a user mode.
Linux:arch/i386/kernel/entry.S;
i386/i386/trap.c em FreeBSD.
- Interrupt Handling
BSD suport interrupt priority level (ipl): 0-31.
Quando saímos do Interrupt Handler verificamos se há alguma interrupçăo
suspenso.
Se o nosso nível for < que o nível corrente, guardamos interrupçăo num
registo especial.
- syscall săo "non-preemptive": só um processo de cada vez.
- Processo pode bloquear num recurso (ie. buffer em memoria):
- Processo chama sleep().
- sleep() coloca processo numa fila, e chama swtch()
para entrar outro processo.
- quando o kernel liberta recurso chama wakeup() para
acordar todos os processos, ie, colocá-los na fila do escalonador.
- outros processos podem precisar do recurso:
wake_one() e wakeprocs().
- Interrupts podem acontecer a qualquer altura: sinc. com
splbio and slpx.
- Mais complicado com multiprocessamento: locks,
semáforos, rw_locks.
- em Linux sleep_on, wake_up_process e
schedule em kernel/sched.c.
- Năo há níveis de interrupçőes: o sistema usa bottom-half
handlers que săo executados depois da interrupçăo.
- Ideia semelhante: DPC de NT (deferred procedure call).
- Verificar kernel/timer.h
- Mecanismo sofisticado de expiraçăo de timers
(run_timer_list executa em tempo constante.
- tasklets: Kernels recentes permitem a bottom-half
handlers de tipos diferentes executar em paralelo (SMP).
- APIC: divisăo de interrupçőes.
Partilha do CPU:
- Escalonador (ver kernel/sched.c em Linux e
kernel/kern_switch.c e i386/i386/swtch.s em
FreeBSD.
- Ideia é usar algoritmo round-robin com múltiplas filas de
propridade.
- Processo mais prioritário entra no CPU mesmo antes do fim do
quantum.
- Em Unix tradicional prioridade é funçăo de nice e de
factor de uso.
- Quando processo bloqueia no Kernel, no regresso recebe
prioridade de Kernel sleep priority (ver
sys/param.h em BSD).
- sleep priorities dependem da razăo pq adormecemos.
- Em Unix fork() cria um novo processo:
- pai retorna de fork() com código do filho;
- filho retorna de fork() com 0.
- Esta é a única diferença entre os 2
- Habitualmente filho executa exec() que faz overlay de
um programa novo.
- Manter fork() e exec() separados:
- permite clones (client-server, prog. par);
- permite fazer setup antes de exec();
- problemas de performance.
- fork() reserva swap, aloca novo PID e proc, inicializa
proc, aloca mapas de traduçăo de endereços, aloca
u-area e copia do pai, altera a u-area com novos
mapas de endereços e swap, adiciona o filho aos processos que
partilham o texto do pai, duplica as áreas de pilhas e dados do pai,
obtém referencias a recursos partilhados, inicializa contexto HW,
pőe o processo runnable e na fila de escalonamento, retorna para o
filho e para o pai.
- evitar cópia: copy-on-write (SYSV) e vfork() (BSD).
- ver kernel/fork.c em Linux e kern/sys_fork.c
em FreeBSD.
- procurar PID: get_pid() em Linux.
- Linux retorna no filho, Unix no pai.
- exec() obtém o executável, verifica permissőes, lę o
cabeçalho, altera ID se SUID ou SGID, copia os argumentos de
exec() e env para kernel space, aloca swap, liberta
data e pilhas antigas, aloca mapas de endereço e inicializa-os,
restaura env e argumentos, reinicializa os signal handlers,
e inicializa contexto HW.
- Ver fs/exec.c em Linux, kern/sys_exec.c em
FreeBSD.
- Em Linux:
- flush_old_exec() limpa;
- open_exec() procura o ficheiro;
- search_binary_handler();
- chama linux_binfmt -> load_binary, eg
load_elf_binary() em fs/binfmt_elf.c;
- Outros formatos: aout, sh, misc, e
em86.
Único processo que năo resulta de fork(). Ver
init/main.c:
init() {
lock_kernel();
do_basic_setup();
/*
* Ok, we have completed the initial
* bootup, and we're essentially up
* and running. Get rid of the initmem
* segments and start the user-mode stuff..
*/
free_initmem();
unlock_kernel();
if (open("/dev/console", O_RDWR, 0) < 0)
printk("Warning: unable to open
an initial console.\n");
(void) dup(0);
(void) dup(0);
\T\pagebreak
/*
* We try each of these until one succeeds.
*
* The Bourne shell can be used instead
* of init if we are
* trying to recover a really broken machine.
*/
if (execute_command)
execve(execute_command,argv_init,envp_init);
execve("/sbin/init",argv_init,envp_init);
execve("/etc/init",argv_init,envp_init);
execve("/bin/init",argv_init,envp_init);
execve("/bin/sh",argv_init,envp_init);
panic("No init found.
Try passing init= option to kernel.");
}
- exit() é chamada ou devido a um signal ou do próprio
processo.
- processos podem comunicar por kill(): -1,
-PG, 0, PID:
kill_something_info().
- exit() desliga sinais, fecha ficheiros, liberta ficheiro
texto e outros recursos como cwd, escreve no log, guarda estatísticas,
muda para SZOMB, faz com que init herde o processo,
liberta memória, envia SIGCHLD para pai, acorda pai, chama
swtch().
- Ver kernel/exit.c em Linux: do_exit() libera
mm, files, fs, chama
exit_notify().
- exit_notify() chama do_notify_parent() e
passa filhos para init().
- do_notify_parent envia SIGNAL para pai e
tenta acordá-lo.
- wait() espera terminaçăo de processos: retorna se já
houver processos mortos, senăo bloqueia. Em qq caso retorna
pid, escreve o status do filho, liberta o proc.
- BSD4.4 fornece wait4() com info de recursos. POSIX
fornece waitpid(). SVR4 tem waitid que fornece
tudo.
- se processo morre depois do pai pertence a init.
- se processo morre antes do pai e este năo chama wait,
processo fica zombie. SVR4 permite usar
SA_NOCLDWAIT sobre SIGCHLD para indicar que pai
năo vai esperar pelos filhos
- Implementado em kernel/exit.c: procura processo no
estado ZOMBIE ou em STOPPED com exit code.
- Aplicaçőes cliente-servidor

- Aplicaçőes Paralelas
- Aplicaçőes Interactivas
- Problemas:
- Preço de fork.
- Partilha de Recursos, como memória.
- Soluçăo: threads dentro do mesmo processo.
- Concorręncia de Sistema: o kernel reconhece múltiplos threads
dentro de um processo.
- Concorręncia para Utilizador: independente do kernel, util para
aplicaçőes concorrentes.
- Concorręncia Dual: kernel reconhece múltiplos threads num processo, e
utilizador pode usar libraria para definir os seus threads.
Problema, separaçăo entre UT e LWP:
- kernel năo pode saber que LWP tem os melhores threads;
- UTs podem perder LWPs, năo suportam paralelismo.
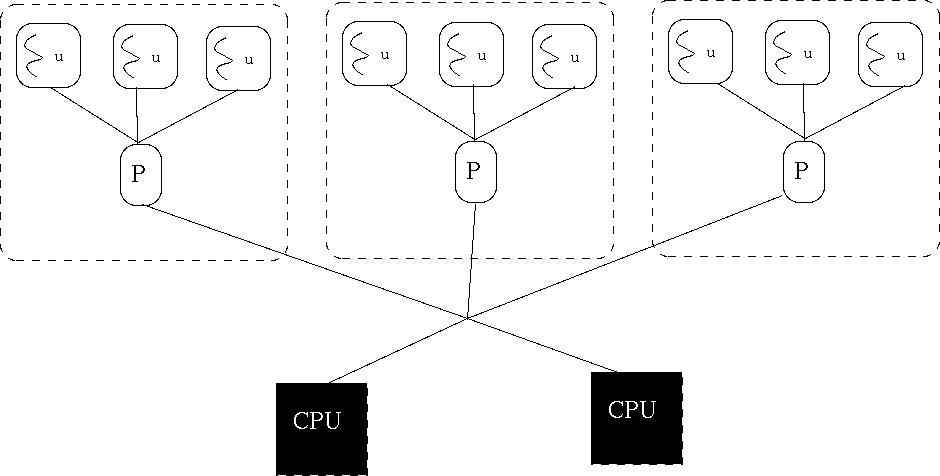

- suporte a fork(): duplicar todos os LWPs ou apenas o que fez
fork()?
- Segunda melhor para exec(), mas problemas com bib.
que tenham os seus próprios LWPs.
- LWPs bloqueados? Possível LWP retornar EINTR, mas tem
que se ter cuidado com fechar ligaçőes de rede. Cuidado com
estruturas de dados externas.
- Registrar fork handler que săo executados antes e
depois de fork().
- Vários LWPs podem aceder ao mesmo fd (um lę, outro faz fseek).
Soluçőes: aplicaçăo resolve o problema, ou kernel suporta random IO
atómico (pread e pwrite)
Gestăo de cwd, credenciais, e mapa de memória (vários brk()
ao mesmo tempo).
- Quem recebe sinais? Todos os LWPs (^Z), um
qq, master, heurísticas, novo LWP?
Sinais como SIGSEGV devem interromper LWP responsavel.
SIGINT é complicado.
Signal Handler geral ou privado? Signal masks devem ser privados.
- Visibilidade fora do processo? Dentro do processo (signal entre LWP)?
- Gestăo das pilhas: o kernel năo pode saber, mas como processar
overflows.
P-threads:
- criar: pthread_create(THREAD, ATTR,ROUTINE,ARG)
- terminar: ímplicito ou por pthread_exit(RETVAL).
- atributos: detachstate, schedpolicy,
schedparam (prioridade), inheritsched,
scope (năo em Linux).
- cancelar outro thread: pthread_cancel(TH)
- Primitivas de sincronizaçăo: mutexes, variáveis de
condiçăo, semáforos, read-write locks.
- handlers: cleanup, at_fork().
- Variáveis privadas a threads: usa TSD indexada por chave.
- Processamento e envio de sinais.
- pthread_join(TH,THREAD_JOIN).
- Implementaçăo:
- LWP para UT;
- Multiple UT num LWP;
- Permita UT ligados e năo ligados. Pode favorecer bound threads

Kernel Threads săo usados para actividade assíncrona
(callouts, STREAMs, escrita no disco) e para suportar LWPs:
- Cópia dos registos
- Informaçăo sobre prioridade e escalonamento
- ptr. para lista de escalonamento ou lista de suspensăo.
- ptr. para pilha
- ptr. para LWP e proc se associado a WLP, +
info sobre LWP.
- ptr. para fila de threads no processo e no sistema.
Kernel organizado como conj. de KTs: alguns LWPs, outros no kernel.
KTs săo preemptible.
Primitivas de sincronizaçăo: semáforos, condiçőes, etc, tentam impedir
inversăo de prioridades.
Cada LWP é associado a um KT durante a sua vida.
Em lwp:
- valores de registos usuário.
- argumentos e resultados para syscalls.
- info. para signals.
- alarmes em tempo virtual; tempo de util. e CPU; outros recursos.
- ptr. para KT.
- ptr. para proc
LWP é swappable, logo máscaras tęm que estar em KT. No SPARC
g7 refere lwp.
Sincronizaçăo como para KT: bloqueantes ou năo.
Signal handlers săo comuns ao processo mas máscaras pertencem ao LWP
(e possivelmente stack).
UT săo implementados por bibliotecas. Podem ser associados a LWPs ou năo
- Thread ID.
- saved register state
- pilha de utilizador.
- máscara de sinais.
- prioridade
- armazenamento local (errno).
Solaris usa mutex e semáforos para interrupts, e usa interrupt
threads para atender a interrupts:
- kernel tradicional bloqueia outros interrupts enquanto serve
interrupt ou usa algumas estruturas de dados.
- evitar o custo de KT: pool de threads, inicializados
parcialmente. Um por cada nível exigindo 8k de espaço.
- Int. handlers operam sem estarem completamente inicializados. Só
săo inicializados se bloquearem.
- Durante a sua execuçăo prendem o thread que foi interrompido.

Chamadas de sistema:
- fork duplica todos os LWPs
- os threads em syscall recebem EINTR.
- fork1 só um thread.
- util se logo antes de exec()
- pread e pwrite fazem
fseek+op.
- Năo existe preadv e pwritev
- programadores podem começar com threads e depois usar LWPs.
Mach suporta:
- Task: objecto com espaço de endereçamento e recursos chamados
port rights.
- Thread: é a unidade de execuçăo com kernel stack, estado, e
escalonável. Se do kernel pertencem ŕ kernel task.
- syscalls manipulam tasks e threads (create, terminate,
suspend, resume, thread_status, thread_mutate e task_threads).
- Biblioteca c-thread fornece interface. Pode ser com
coroutine (precisa de cthread_yield())
threads, ou tasks.
Task contém:
- ptr. para mapa de endereços (VM).
- ptr. para lista de threads na task.
- ptr. para o processor set da task.
- ptr. para utask (compatibilidade com Unix).
- portas e mais info IPC.
Thread contém:
- Links para fila de escalonador ou de wait.
- ptr. para task e processor set.
- links para lista de threads da task e proc. Set.
- ptr. para PCB com contexto.
- ptr. para pilha de kernel.
- Estado de escalonamento (pronto, suspenso, bloqueado,...)
- Info. de escalonomento (PRIO, policy, uso de CPU).
- ptr para uthread e utask
- IPC.
Baseado em Mach 2.5:
- Externamente: Unix.
- Internamente: Mach.
- área-u é substituida por:
- utask: vnode (cwd, root), proc, signal
handlers, open file descriptors, cmask, recursos.
- uthread: registos, travessia de caminhos, sinais,
handlers para threads.
- macros permitem converter de u-area para as novas
regiőes.
- proc esvaziada por task e thread:
muitos campos năo săo usados.
- fork cria um novo thread.
Problema:
- Cada thread tem pilha com pelo menos 4KB: overhead.
- Unix usa modelo de processos: cada thread tem uma pilha e pode
bloquear sem salvar a sua pilha
- Modelo de interrupts: uma única pilha do kernel, e o processo
interrompido tem que salvar o seu estado.
- Primeiro modelo é melhor quando processo tem muito estado. Se
tiver pouco estado, segundo é o melhor.
Mach 3.0 usa continuaçőes, uma funçăo a executar quando o thread
bloqueia:
- Uteis quando há pouco estado (exemplo, no fim de page fault
handling enquanto espera pelo resultado de um read).
- Se kernel novo e antigo tęm continuaçőes kernel pode transferir
pilha directamente: evita TLB e cache misses.
- cliente chama mach_msg() numa port e espera que
servidor responda com mach_msg(). Se servidor năo pronto,
mensagem é colocada numa fila.
- Se o emissor tem o receptor ŕ espera, pode passar-lhe a pilha e
bloquear com mach_msg_continue(). O receptor execute
imediatamente usando a pilha do emissor onde já está a mensagem!
- Ideal para hot-spots (típicos em interface pequena, como num
micro-kernel).

- Bloco KProcess: dispatcher object, ptr. para process
pages, KTHREADs para o processo, prioridade base, quantum,
afinidade, tempos em kernel e usuário.
- PID: ID do processo e pai, nome da imagem, "window station".
- Bloco para Quota.
- Descriptores de Espaço de Memória Virtual.
- Info. sobre conjunto de Trabalho.
- Info sobre memória virtual.
- Porta para Excepçőes.
- Porta para Debugging.
- Token de Acesso (profile de segurança).
- Tabela de handles para objectos.
- W32Process e PEB.
- Sempre mapeado no endereço 0x7FFDF000.
- Info usada pelo carregador, gestor de heap, e outros DLLs Win32.
- Inclui:
- Endereço base da imagem;
- Lista de módulos;
- Dados locais a threads;
- Time-out de secçăo critica;
- Número de heaps;
- Tamanho da heap;
- Ptr. para heap;
- handle partilhada para GDI;
- versăo do OS e da imagem;
- Afinidade.
Integrar UTs e Kernel:
- Kernel aloca CPU(s);
- Biblioteca escalona.
- Biblioteca informa sobre eventos que afectam alocaçăo: pede mais
CPUs, libertar CPU.
- Kernel controla alocaçăo e pode retirar CPUs.
- Mas, quando biblioteca tem CPU é ela quem escolhe que UT
corre lá.
- Kernel deve informar biblioteca sobre mudanças.
Ideia veio de Anderson
- Upcall:
- Kernel chama biblioteca;
- Scheduler Activation:
- contexto que pode ser usado para correr
um UT (semelhante a LWP).
- Quando kernel faz upcall passa ou retira activaçăo para a
biblioteca.
- Kernel năo faz timeslice sobre activaçőes.
- Bloqueio:
- kernel cria uma nova activaçăo e faz upcall.
- bibl. guarda activaçăo antiga, liberta-a, informa o kernel.
- bibl. escalona novo UT.
- Quando operaçăo conclui, nova upcall do kernel: nova
activaçăo. Pode dar CPU, ou remover uma activaçăo.
Esquema extremamente rápido.
vitor@cos.ufrj.br