UNIVERSIDADE FEDERAL DO RIO DE JANEIRO
CURSO DE BACHARELADO EM INFORMÁTICA
CADEIRA DE PROGRAMAÇÃO EM LÓGICA
Marcello Gonçalves Rego
Junho de 1998
SQL x PROLOG
Introdução
Sistemas de Gerência de Banco de Dados Relacionais são
caracterizados pela maneira com que eles representam os dados e pelas operações
que podem ser desempenhadas sobre os dados . Aplicações de
Banco de Dados Relacionais podem ser criadas em Prolog . O Banco de Dados
Prolog e os métodos para acessá-lo se parecem com o modelo
relacional . Nesse documento examinarei os componentes de um Sistema de
Gerência de Banco de Dados e como operações SQL podem
ser desempenhadas em Prolog . O dicionário de dados armazena as
informações sobre as tabelas relacionadas . E para manejar
um dicionário de dados , o sistema deve ser hábil a :
- Criar uma nova definição de tabela .
- Mudar uma definição e as informações já
contidas em uma tabela . Em SQL , essa operação é
restrita à adicionar novas colunas ; colunas não podem ser
removidas .
- Apagar uma definição de tabela e a informação
contida nessa tabela .
Mostrarei como as operações sobre esse dicionário
de dados podem ser manuseadas em Prolog . Consultas para recuperar informações
de banco de dados podem ser escritas como perguntas em Prolog . SQL provê
a declaração SELECT como uma maneira de requisitar
informação do banco de dados . A declaração
SELECT determina quais colunas , tabelas , e linhas são requisitadas
. Esse documento mostra como diferentes operações com a declaração
SELECT , podem ser manuseadas em Prolog .
Componentes de um Sistema de Gerência de Banco de Dados
Um Sistema de Gerência de Banco de Dados é constituído
de 4 componentes básicos :
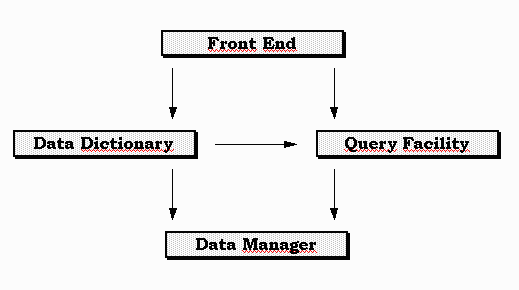
Fig. 1 - Componentes de uma Sistema de Gerência de Banco
de Dados Relacional .
Front End
O front end aceita entradas do usuário . Ele faz uma
análise inicial das entradas do usuário para determinar se
o usuário utilizou a sintaxe de consulta ou comando corretos . Então
ele passa as entradas do usuário para o data dictionary para
definir novas tabelas ou para a query facility para acessar as informações
armazenadas no banco de dados . O front end também retorna
informações para o usuário , ou mais importante ,
retorna os resultados das consultas ou os erros que possam ter acontecido
.
Data Dictionary
O data dictionary define a terminologia com que o usuário
pode formular consultas . Ele mantém um catálogo dos nomes
das tabelas e dos campos definidos para essas tabelas . Informações
não podem ser adicionadas à base de dados a não ser
que estejam conformes com a definição das tabelas . Dada
a flexibilidade da linguagem Prolog em manusear dados , parece se tornar
desnecessário a existência de um data dictionary .
Prolog permite , a qualquer momento , criar termos para armazenar qualquer
tipo de informação . Ele não restringe o tipo de informação
que pode ser entrada . Esse é precisamente o porque da necessidade
de um data dictionary — para manter a ordem no banco de dados .
O data dictionary pode checar se as entradas do usuário possuem
o número correto de argumentos e que essa informação
é armazenada sempre da mesma forma . Pode também conter informação
do tipo dos dados para ter certeza que os argumentos sempre serão
de informações similares .
Query Facility
A query facility adiciona informação ou retorna
informação da base de dados . Uma consulta é formada
por termos do data dictionary , isto é , o usuário
se refere às tabelas e às colunas pelos nomes do data
dictionary . A query facility traduz a representação
do data dictionary na consulta para uma pergunta Prolog . O resultado
de qualquer consulta é outra tabela , embora seja somente uma parte
de outra tabela ou a combinação de mais de uma tabela . SQL
distingue entre tabelas " lógicas " e " físicas
" . Uma tabela física é a forma como as informações
são armazenadas no banco de dados ; uma tabela lógica é
uma tabela resultante de uma consulta . Tabelas lógicas não
existem no banco de dados e não afetam como as informações
são armazenadas internamente no banco de dados . Em Prolog as informações
são armazenadas como estruturas Prolog . Em algum momento , uma
estrutura pode ser usada como um fato e armazenada no banco de dados .
Em outro , pode ser usada como uma meta e retornar informação
do banco de dados . Uma estrutura pode ser convertida em uma lista , o
que torna possível a procura por argumentos específicos ou
adicionar argumentos a estrutura . Depois , a lista pode ser convertida
de volta em uma estrutura . Portanto , as rotinas aceitarão consultas
que se referem à tabelas ou colunas pelo seu nome no data dictionary
. Elas serão convertidas em perguntas válidas em Prolog .
Argumentos adicionais para as rotinas determinarão se certos argumentos
estão instanciados ou se testes adicionais deverão ser realizados
.
Data Manager
O banco de dados interno Prolog fornece mecanismos para armazenar e
acessar termos . Um sistema de gerência de banco de dados relacional
pode tirar vantagens do banco de dados interno Prolog , isto é ,
tabelas podem ser armazenadas na forma de estruturas Prolog . Acesso a
essas tabelas é fornecido pelo mecanismo interno Prolog para armazenar
e recuperar informações . Prolog fornece armazenamento seqüencial
e métodos de acesso à base de dados .Você não
precisa de primitivas de manuseamento de código especial de dados
. Além disso , armazenamento e métodos de acesso alternados
podem ser empregados.
Planejando o Banco de Dados
Quando escrevemos um programa para armazenar dados numa coleção
de registros , você deve também utilizar informações
sobre os atributos dos registros . Em meu exemplo , utilizarei as seguintes
informações :
- O título do CD ;
- O nome da banda ;
- O nome da gravadora ;
- Os títulos das músicas no CD ;
- A data do lançamento ;
- Os nomes dos membros ( músicos ) da banda ;
- Os instrumentos que cada membro ( músico ) toca ;
Os objetos que serão armazenados são divididos em duas
categorias : cd e músicos . Inicialmente , você
pode criar uma tabela para cada uma dessas categorias , como mostrado abaixo
:
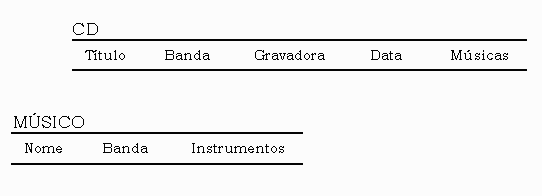
Fig. 2 - Plano Inicial do Banco de Dados
Essa primeira tentativa de organização é bem lógica
, porque todas as informações relatadas estão unidas
. Entretanto essa organização pode ser melhorada . Uma organização
otimizada não deve ser somente de agrupar objetos logicamente para
o usuário , mas também permitir ao sistema a atualizar e
apagar informação eficientemente . Normalização
é o método que é usado para reorganizar melhor a informação
no banco de dados , onde cada objeto é definido uma e somente uma
vez . Existem cinco " formas normais " que se pode aplicar sobre
seu banco de dados para determinar se este possui uma organização
ótima , mas somente a primeira forma normal será tratada
nesse exemplo .
Considere a relação CD . Para cada CD , existem atributos
que ocorrem uma vez e atributos que ocorrem mais de uma vez . Por exemplo
, só existe uma gravadora para um CD , mas podem existir muitas
músicas num CD . A definição atual da tabela CD não
é eficiente . Para atualizar uma música é necessário
atualizar todas as outras ; para recuperar uma música é necessário
recuperar todas as músicas . Uma relação está
na primeira forma normal ( 1NF ) quando todos os seus atributos são
simples , objetos átomos . Portanto , uma lista de músicas
não pode aparecer numa relação se ela está
na primeira forma normal . Para ter essa informação de acordo
com a primeira forma normal , a tabela CD deve ser dividida em duas tabelas
, como mostrado na fig. 3 . Uma contêm o título , nome da
banda , gravadora , e data ; a outra contêm o título do CD
e o título das músicas .

Fig. 3 - Informação armazenada na primeira forma
normal .
Quando você separou as músicas da relação
CD , você duplicou o registro título em cada instância
de uma música . Como resultado a informação não
está compactada , mas nesse caso a duplicação não
faz diferença para a aplicação , no outro caso sim
. A relação MÚSICO também pode ser colocada
na forma normal . Um músico pode tocar em várias bandas e/ou
vários instrumentos . Então um arranjo diferente para a informação
dos músicos pode ser visto na fig. 4 .

Fig. 4 - Informação dos Músicos em primeira
forma normal .
Embora a informação seja quebrada em mais tabelas , nenhuma
informação é perdida . As tabelas são conectadas
através do compartilhamento de atributos das relações
. A fig. 5 mostra como as tabelas no banco de dados são conectadas
. A coluna que conecta uma tabela com outra é chamada de "
chave estrangeira " , ou foreing key ( FK ) .
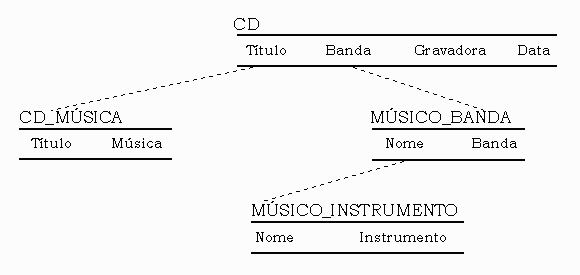
Fig. 5 - Organização final do Banco de Dados
Um sistema de gerência de banco de dados relacional pode requerer
que cada tabela tenha uma " chave primária " , ou "
primary key " ( PK ) . A chave primária é uma coluna
, ou grupo de colunas , que mantém cada linha de uma tabela única
. Prolog não necessita que termos no banco de dados sejam únicos
. É possível existir termos em Prolog que sejam idênticos
a outros . Cada um é tratado como um objeto único . Portanto
essa flexibilidade torna Prolog uma excelente linguagem de programação
, mas isso pode se tornar um problema quando Prolog é usado como
uma linguagem gerenciadora de banco de dados. Prolog não tem mecanismos
internos para manter a integridade das tabelas . A integridade deve ser
imposta ao banco de dados pela aplicação .
O Data Dictionary
O data dictionary mantém informações sobre
cada tabela no banco de dados . Cada entrada no data dictionary
é um template da tabela que está sendo definida , recebendo
o nome da tabela e os nomes das suas colunas . Em SQL as informações
são adicionadas ao data dictionary com o comando CREATE
TABLE . Em Prolog , a definição da tabela pode ser escrita
como uma coleção de estruturas . Por exemplo :
tabela( cd( título , banda , gravadora , data ) ) .
tabela( músico_banda( nome , banda ) ) .
tabela( músico_instrumento( nome, instrumento ) ) .
tabela( cd_música( título , música ) ) .
Em sistemas SQL , o data dictionary também contém
informação sobre o tipo dos dados . Ele pode definir tipo
de dados de objetos , se os objetos podem ser nulos e quais limites de
valor são válidos para objetos numéricos . A linguagem
Prolog não é sensível ao tipo como SQL . Entretanto
, um sistema Prolog pode se tornar mais sensível aos tipos se for
adicionada a informação sobre os tipos de dados no data
dictionary . Você pode adicionar essa informação
à definição da tabela assim :
tabela( músico_instrumento( nome : atom , instrumento : atom
) ) .
Ou separar as informações assim :
tabela( músico_instrumento( nome , instrumento ) )
.
.
.
.
tipo( nome( atom , notnull ) ) .
tipo( instrumento( atom , null ) ) .
Em ambos os casos você terá que escrever predicados para
checar se o tipo de dados de um objeto está conforme a especificação
de tipos no data dictionary quando for inserir uma nova linha na
tabela .
O Banco de Dados
Agora que já sabemos como estruturar as informações
, você pode começar a armazenar dados nas tabelas . Em Prolog
, cada nome de tabela é um functor , e cada coluna é um argumento
do functor . Aqui algumas informações sobre dois CD´s
e como serão armazenados em nosso banco de dados CD’s em Prolog
:
cd( ‘ Ten ’ , ‘ Pearl Jam ’ , ‘ Epic ’ , 1991 ) .
cd( ‘ Never Mind ’, ‘ Nirvana ’ , ‘ Virgin Songs ’ , 1992 ) .
músico_banda( ‘ Jeff Ament ’ , ‘ Pearl Jam ’ ) .
músico_banda( ‘ Stone Gossard ’ , ‘ Pearl Jam ’ ) .
músico_banda( ‘ Jack Irons ’ , ‘ Pearl Jam ’ ) .
músico_banda( ‘ Mike McCready ’ , ‘ Pearl Jam ’ ) .
músico_banda( ‘ Eddie Vedder ’ , ‘ Pearl Jam ’ ) .
músico_banda( ‘ Kurt Cobain ’ , ‘ Nirvana ’ ) .
músico_banda( ‘ David Grohl ’ , ‘ Nirvana ’ ) .
músico_banda( ‘ Chris Novoselic ’ , ‘ Nirvana ’ ) .
músico_instrumento( ‘ Jeff Ament ’ , ‘ Bass ’ ) .
músico_instrumento( ‘ Jeff Ament ’ , ‘ Vocals ’ ) .
músico_instrumento( ‘ Stone Gossard ’ , ‘ Guitar ’ ) .
músico_instrumento( ‘ Stone Gossard ’ , ‘ Vocals ’ ) .
músico_instrumento( ‘ Jack Irons ’ , ‘ Drums ’ ) .
músico_instrumento( ‘ Jack Irons ’ , ‘ Percussion ’ ) .
músico_instrumento( ‘ Mike McCready ’ , ‘ Guitar ’ ) .
músico_instrumento( ‘ Eddie Vedder ’ , ‘ Vocals ’ ) .
músico_instrumento( ‘ Eddie Vedder ’ , ‘ Guitar ’ ) .
músico_instrumento( ‘ Kurt Cobain ’ , ‘ Vocals ’ ) .
músico_instrumento( ‘ Kurt Cobain ’ , ‘ Guitar ’ ) .
músico_instrumento( ‘ David Grohl ’ , ‘ Drums ’ ) .
músico_instrumento( ‘ David Grohl ’ , ‘ Vocals ’ ) .
músico_instrumento( ‘ Chris Novoselic ’ , ‘ Bass ’ ) .
músico_instrumento( ‘ Chris Novoselic ’ , ‘ Vocals ’ ) .
cd_música( ‘ Ten ’ , ‘ Once ’ ) .
cd_música( ‘ Ten ’ , ‘ Even Flow ’ ) .
cd_música( ‘ Ten ’ , ‘ Alive ’ ) .
cd_música( ‘ Ten ’ , ‘ Why Go ’ ) .
cd_música( ‘ Ten ’ , ‘ Black ’ ) .
cd_música( ‘ Ten ’ , ‘ Jeremy ’ ) .
cd_música( ‘ Ten ’ , ‘ Oceans ’ ) .
cd_música( ‘ Ten ’ , ‘ Porch ’ ) .
cd_música( ‘ Ten ’ , ‘ Garden ’ ) .
cd_música( ‘ Ten ’ , ‘ Deep ’ ) .
cd_música( ‘ Niver Mind ’ , ‘ Smells Like Teen Spirits ’
) .
cd_música( ‘ Niver Mind ’ , ‘ In Bloom ’ ) .
cd_música( ‘ Niver Mind ’ , ‘ Come As You Are ’ ) .
cd_música( ‘ Niver Mind ’ , ‘ Breed ’ ) .
cd_música( ‘ Niver Mind ’ , ‘ Lithium ’ ) .
cd_música( ‘ Niver Mind ’ , ‘ Polly ’ ) .
cd_música( ‘ Niver Mind ’ , ‘ Territorial Pissings ’ ) .
cd_música( ‘ Niver Mind ’ , ‘ Drain You ’ ) .
cd_música( ‘ Niver Mind ’ , ‘ Lougue Act ’ ) .
cd_música( ‘ Niver Mind ’ , ‘ Stay Away ’ ) .
cd_música( ‘ Niver Mind ’ , ‘ On A Plain ’ ) .
cd_música( ‘ Niver Mind ’ , ‘ Something In The Way ’ ) .
Em SQL , a informação é adicionada à tabela
com o comando INSERT . Esse comando tem a seguinte forma geral :
INSERT INTO table-name VALUES ( column1 , column2 , ... ) ;
Em Prolog o predicado correspondente seria :
insert( Table , Args , Term ) :- Term =.. [Table|Args] ,
Esse predicado utiliza o nome da tabela e uma lista de argumentos .
Ele retorna uma estrutura Prolog (Term) , criada a partir dessas
informações . O predicado assertz adiciona o Term
ao banco de dados .
Por exemplo , para adicionar uma música para o CD ‘ Never Mind
’ , você deverá usar o predicado insert dessa forma :
? - insert( cd_música , [‘ Never Mind ’ , ‘ In Bloom ’] ,
Term ) .
Insert usa um predicado chamado univ ( =.. ) para construir o
Term apropriado .
Tranformando SQL Queries em Prolog Questions
Em um sistema SQL , a informação é recuperada com
o comando SELECT , que possui a seguinte forma geral :
Para construir Prolog questions através da representação
de seu data dictionary , você deve usar os três predicados
, functor , arg , e univ :
- functor( Structure , Name , Arity ) - Localiza a tabela correta
e cria uma questão Prolog válida para acessar a tabela .
- arg( Position , Structure , Value ) - Acessa o argumento especificado
numa estrutura .
- Structure =.. List ( Univ ) - Permite manipular um termo como
uma list ou uma structure quando uma forma for mais conveniente que outra
.
Retornando todas as instâncias de todas as colunas
Esse primeiro exemplo retorna todas as informações contidas
na tabela músico_instrumento . O resultado é uma tabela
como mostrada na fig. 6 .

Fig. 6 - Uma tabela mostrando todas as instâncias de todas
as colunas .
Em SQL , a consulta é escrita :
A forma equivalente em Prolog é escrita :
? - músico_instrumento(X,Y) .
Para gerar essa pergunta dado somente o nome da tabela , você
pode usar o predicado como mostrado abaixo :
from( Functor , Table , Query ) :- tabela( Table ) ,
functor( Table , Functor , ArgC ) ,
functor( Query , Functor , ArgC ) .
O predicado usa o data dictionary para localizar a primeira
definição da tabela cujo funtor iguala-se com o argumento
Functor . A primeira chamada para o predicado functor testa
se a definição correta na tabela é encontrada e retorna
o número de argumentos da estrutura . A segunda chamada para functor
cria uma estrutura duplicada que não tem instânciadas variáveis
com argumentos . Quando você chama o predicado from assim :
? - from( músico_banda , Table , Query ) .
A variável Table se torna instânciada pela estrutura
definida no data dictionary , músico_banda( nome , banda
) , e a variável Query se torna instânciada pela
pergunta Prolog músico_banda( X, Y ) . A consulta pode retornar
todas as linhas da tabela músico_banda quando usada como
um goal num fail loop .
Retornando somente algumas instâncias
O próximo exemplo retorna somente os músicos que tocam
guitarra . Em efeito , especificando guitarra , a consulta elimina todas
as linhas que não contenham guitarra na coluna instrumento . Em
SQL , a consulta é escrita :
Em Prolog , a consulta é escrita :
? - músico_instrumento( X , guitar ) .
Gerar essa pergunta Prolog é um pouco mais difícil que
a anterior . Depois de criar a estrutura geral , você deve instanciar
um argumento e deixar o resto dos argumentos como variáveis . A
estrutura geral pode ser criada com o predicado from :
from( Functor , Table , Structure ) .
Depois , a correta posição é encontrada na estrutura
geral para guardar o valor do WHERE . Nesse exemplo , você
precisa descobrir a posição do argumento instrumento . Essa
informação está armazenada na entrada do data dictionary
:
tabela( músico_banda( nome , instrumento ) ) .
A definição da tabela é então passada para
o predicado que irá contar os argumentos até encontrar o
desejado . Nesse predicado , chamado nth_arg , o primero argumento
( Arg ) é o nome do argumento que precisa ser instanciado
. O segundo argumento ( Table ) é a estrutura que contém
a definição da tabela . O terceiro argumento ( N )
é a variável que nth_arg retorna , o número
de argumentos .
nth_arg( Arg , Table , N ) :- Table =.. Z ,
ctr_set( 0 , 0 ) ,
nth_member( Arg , Z ) ,
ctr_is( 0 , N ) .
A primeira unificação do predicado nth_arg converte
a definição da tabela músico_banda em uma lista
, então uma variação do predicado member ,
o predicado nth_member é chamado para contar os elementos
da lista . O predicado nth_member apenas incrementa um contador
até localizar o argumento desejado .
nth_member( X , [X| _ ] ) .
nth_member( X , [ _ |Y] ) :- ctr_inc( 0 , _ ) ,
Os predicados auxiliares são :
ctr_set( Counter,Value ) :- recorded( Counter , _ , Ref ) , replace(
Ref , Value ) .
ctr_set( Counter , Value ) :- recorda( Counter , Value , _ ) .
ctr_is( Counter , Value ) :- recorded( Counter , Value , _ ) .
ctr_inc( Counter , Value ) :- recorded( Counter , Value , Ref ) ,
C1 is Counter + 1 , replace( Ref , C1 ) .
ctr_dec( Counter , Value ) :- recorded( Counter , Value , Ref ) ,
C1 is Counter - 1 , replace( Ref , C1 ) .
Todos esses passos são feitos pelo predicado where . Ele usa
o nome da tabela , o argumento instanciado , e o valor do argumento . Ele
retorna a questão Prolog no quarto argumento .
where( Functor , Arg , Val , Query ) :- from( Functor , Table , Query
) ,
nth_arg( Arg , Table , N ) ,
arg( N , Query , Val ) .
Quando você chama where assim :
? - where( músico_instrumento , instrumento , guitar , Query
) .
O argumento Query é instanciado por músico_instrumento(
X , guitar ) , que irá retonar todos os músicos que tocam
guitarra .
Retornando somente algumas colunas
O próximo exemplo retorna as colunas título e banda
da tabela cd . Em SQL , a consulta é escrita :
SELECT título , banda FROM cd ;
Em Prolog , a consulta é escrita :
? - cd( Title , Band , _ , _ ) .
O método para gerar a consulta é o mesmo usado anteriormente
. Entretanto , a rotina de saída somente mostrará as colunas
nomeadas na consulta . O predicado é chamado select , o qual
dado uma lista de nomes de argumentos e o nome da tabela , ele gera a consulta
e imprime a tabela resultante .
select( Argvals , Functor ) :- from( Functor , Table , Query ) ,
get_nums( Argvals , Table , Argnums ) ,
get_instance( Query , Argnums ) .
Para imprimir somente as colunas desejadas , select converte
a lista de nomes de argumentos em uma lista de suas correspondentes posições
na tabela . O predicado chamado get_nums gera a lista de números
de argumentos da lista de nomes de argumentos . Ele se chama recursivamente
para achar o número de argumentos para cada argumento na lista .
get_nums( [ ] , _ , [ ] ) .
get_nums( [H|T] , Table , [N|Argnums] ) :- nth_arg( H , Table , N
) ,
get_nums( T , Table , Argnums ) .
O predicado get_instance usa a consulta e a lista dos números
de argumentos para executar a consulta e determinar quais colunas imprimir
. As colunas são postas numa lista e passadas para a rotina output
.
get_instance( Query , Argnums ) :- call( Query ) ,
get_columns( Query , Argnums , List ) ,
output( List ) , fail .
get_instance( _ , _ ) .
get_columns( Query , [ ] , [ ] ) .
get_columns( Query , [H|T] , [Val|List] ) :- arg( H , Query , Val
) ,
get_columns( Query , T , List ) .
A rotina output recursivamente imprime os argumentos da lista
.
output( [ ] ) :- nl .
output( [H|T] ) :- write( H ) , tab( 4 ) , output( T ) .
Quando você chama select com a lista [título
, banda] e a tabela cd , ele retorna a seguinte tabela :
? - select( [título , banda] , cd ) .
- Ten Pearl Jam
- Never Mind Nirvana
Predicados SQL
A versão do predicado where descrito anteriormente usava
a unificação para verificar igualdade . Ele só podia
checar se um argumento era igual a um valor . A parte WHERE de uma
consulta pode fazer outros testes para determinar quais informações
deve retornar .
- Predicados de comparação para testar ‘ < ’ , ‘ >
’ , ‘ <>’ , ‘ = ’ .
- O predicado BETWEEN determina se um argumento está dentro
de valores limites .
- O predicado IN determina se um argumento está dentro
de um conjunto de valores .
- Conjunções determinam se mais de uma condição
é verdadeira ; disjunções determinam se uma ou outra
condição é verdadeira .
Com a intenção de adicionar esses testes à consulta
, o predicado where deve ser reescrito . A nova versão do
where usa from para gerar a forma geral da consulta . Ele
usa get_nums para retornar a lista de números de argumentos
envolvidos no teste . Então ele chama o predicado chamado do
, fornecendo o número de argumentos , o operador , os valores envolvidos
no teste , e a consulta .
where( Functor , ( Arg , Op , Val ) , Query ) :- from( Functor ,
Table , Query ) ,
nth_arg( Arg , Table , Argnum ) ,
do( ( Argnum , Op , Val ) , Query ) .
O predicado do executa a consulta e extrai o argumento da estrutura
que é retornada por call . Ele então faz o teste específico
no valor atual do argumento . Univ retira a cabeça da estrutura
e passa os argumentos para output como uma lista . Esses passos
são colocados num fail loop e todas as instâncias no banco
podem ser testados e impressos .
do( ( Arg , Op , Val ) , Query ) :- call( Query ) ,
arg( Arg , Query , X ) ,
test( X , Op , Val ) ,
Query =.. [ _ |L] ,
output( L ) , fail .
do( _ , _ ) .
O teste que deverá ser feito depende do predicado que é
passado para o argumento Op . O predicado test pode fazer
cada um dos testes permitidos numa consulta SQL , como descrito abaixo
.
Predicados de comparação
Existem dois tipos de predicados de comparação em Prolog
. O primeiro faz comparação aritmética ( para dados
numéricos ) ; o segundo faz comparações textuais (
para dados não-numéricos ) . O predicado test faz
a comparação especificada pelo argumento operador .
test( X , Op , Val ) :- Goal =.. [Op,X,Val] ,
Com o predicado test definido dessa forma , uma consulta SQL
pode pedir uma tabela com todos os CD’s feitos depois de 1990 :
Em Prolog , essa consulta é escrita :
? - where( cd , ( data , > , 1990 ) , X ) .
O predicado BETWEEN
O predicado BETWEEN torna possível especificar um intervalo
de valores como parte da declaração WHERE . Uma linha
é incluída na tabela se um certo valor fica entre dois valores
. Por exemplo , uma consulta SQL para retornar os CD’s gravados entre 1990
e 1992 :
O predicado between em Prolog pode testar se um valor está
dentro de dois limites . Uma coluna está entre um valor alto e um
valor baixo se é maior ou igual ao valor baixo e menor e igual ao
valor alto :
between( Col , Low , High ) :- Col >= Low , Col =< High .
Agora você pode usar essa consulta para retornar todos os CD’s
gravados entre 1990 e 1992 :
? - where( cd , ( data , between , ( 1990 , 1992 ) ) , X ) .
A consulta retorna a tabela :
Ten Pearl Jam Epic 1991
Never Mind Nirvana Virgin Songs 1992
O predicado IN
O predicado IN permite que uma lista de valores seja parte da
declaração do WHERE . Uma linha é incluída
na tabela se uma certa coluna contem um valor igual a um valor dentro da
lista . Por exemplo , uma consulta SQL para pedir o nome da banda onde
Mike McCready e Eddie Vedder tocam :
SELECT * FROM músico_banda WHERE nome IN [‘ Mike McCready
’ , ‘ Eddie Vedder ’ ] ;
O predicado IN simplesmente checa se o valor de um argumento
é membro de uma lista .
in( X , L ) :- member( X , L ) , ! .
member( X , [X| _ ] ) .
member( X , [ _ | L] ) :- member( X , L ) .
Where pode agora encontrar o nome das bandas que Mike McCready
e Eddie Vedder tocam :
? - where( músico_banda , ( nome , in , [‘ Mike McCready ’
, ‘ Eddie Vedder ’] ) , X ) .
A consulta resulta a tabela :
Mike McCready Pearl Jam
Eddie Vedder Pearl Jam
Conjunção e Disjunção
Uma conjunção é um conjunto de condições
separadas pela palavra AND . Todas as condições devem
suceder para que uma coluna seja incluída em uma tabela . No seguinte
exemplo , a consulta SQL procura uma coluna nome igual a ‘ Kurt Cobain
’ e coluna instrumento igual a ‘ Vocals ’ .
Uma disjunção é um conjunto de condições
separadas pela palavra OR . Somente uma das condições
deve suceder para que uma coluna seja incluída em uma tabela . No
seguinte exemplo , a consulta SQL procura uma coluna nome igual a ‘ Jeff
Ament ’ ou uma coluna instrumento igual a ‘ Vocals ’ .
Ambos AND e OR podem ser manipulados em Prolog com um
versão modificada do predicado where que utiliza dois conjuntos
de variáveis ( Argument , Operator , Value
) separados por um and ou or .
where( Functor , ( Arg1 , Op1 , Val1 ) , Op , ( Arg2 , Op2 , Val2
) , Query ) :- from( Functor , Table , Query ) ,
nth_arg( Arg1 , Table , Argnum1 ) ,
nth_arg( Arg2 , Table , Argnum2 ) ,
do( ( Argnum1 , Op1 , Val1 ) , Op , ( Argnum2 , Op2 , Val2 ) , Query
) .
Uma nova versão do predicado do também é
necessária . A primeira cláusula do predicado do sucede
se o operador é um and . Ele executa a consulta e localiza
os dois argumentos que serão testados . Então é chamado
o predicado test para testar cada condição . Devido
às duas chamadas para o predicado test serem separadas por
uma vírgula ( operador Prolog de conjunção ) , ambos
os testes devem suceder para que a instância seja incluída
na tabela .
do( ( Arg1 , Op1 , Val1 ) , and , ( Arg2 , Op2 , Val2 ) , Query )
:- call( Query ) ,
arg( Arg1 , Query , X1 ) ,
arg( Arg2 , Query , X2 ) ,
test( X1 , Op1 , Val1 ) , test( X2 , Op2 , Val2 ) ,
Query =.. [ _ |L] ,
output( L ) , fail .
A segunda cláusula do predicado do sucede se o operador
é um or . Ele também chama a consulta e localiza os
dois argumento envolvidos no teste . Entretanto as duas chamadas para o
predicado test são separadas por um ponto-e-vírgula
( operador Prolog de disjunção ) . Protanto , somente um
dos testes deve suceder para que a instância seja incluída
na tabela .
do( ( Arg1 , Op1 , Val1 ) , or , ( Arg2 , Op2 , Val2 ) , Query )
:- call( Query ) ,
arg( Arg1 , Query , X1 ) ,
arg( Arg2 , Query , X2 ) ,
( test( X1 , Op1 , Val1 ) ; test( X2 , Op2 , Val2 ) ) ,
Query =.. [ _ |L] ,
output( L ) , fail .
Uma terceira cláusula do predicado do simplesmente sucede
. Ele é executado quando não são achadas mais instâncias
no banco de dados .
O predicado where pode ser chamado com a conjunção
de objetivos :
? - where( músico_instrumento , ( nome , = = , ‘ Kurt Cobain
’ ) , and , ( instrumento , = = , ‘ Vocals ’ ) , X ) .
A consulta resulta a tabela :
Kurt Cobain Vocals
O predicado where pode ser chamado com a disjunção
de objetivos :
? - where( músico_instrumento , ( nome , = = , ‘ Jeff Ament
’ ) , or , ( instrumento , = = , ‘ Vocals ’ ) , X ) .
A consulta resulta a tabela :
Jeff Ament Bass
Jeff Ament Vocals
Stone Gossard Vocals
Eddie Vedder Vocals
Kurt Cobain Vocals
David Grohl Vocals
Chris Novoselic Vocals
Operadores de Aritmética
SQL permite que operadores de aritmética sejam utilizados sobre
as informações do banco de dados . Operadores de aritmética
são postos na linha da consulta SELECT da seguinte forma
:
A tabela mostra operadores de aritmética disponíveis em
Prolog e SQL .
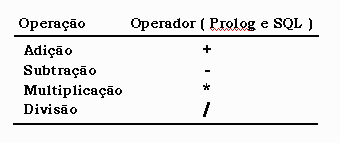
Outras operações aritméticas são disponíveis
em SQL . Estas são feitas pelas funções internas SUM
, COUNT , MIN , MAX , e AVG . Devemos escrever
predicados para manipular essas operações em Prolog . Operações
aritméticas retornam informações que não existem
no banco de dados . Elas derivam novas informações das informações
armazenadas no banco . Quando usadas , a consulta produz uma coluna de
informações que não foi pré-definida no data
dictionary . Sistemas SQL provêm uma maneira de nomear essa coluna
como parte da consulta . De outra forma , essa informação
seria colocada numa coluna sem cabeçalho . Nenhuma das informações
do banco de dados CD’s poderia ser usada em operações aritméticas
. Para os exemplos a seguir , será necessário adicionar uma
nova tabela ao banco de dados . Uma nova tabela para armazenar a informação
sobre o rendimento de cada CD .
tabela( rendimento( título , cópias , preço_unid
) ) .
Você pode adicionar essas informações no banco da
seguinte forma :
insert( rendimento , [‘ Ten ’ , 700.000 , 20] , _ ) .
insert( rendimento , [‘ Never Mind ’ , 650.000 , 15] , _ ) .
Essas informações podem ser manipuladas de várias
maneiras usando operadores aritméticos .
Fazendo cálculos
O total de rendimentos de cada CD pode ser calculado multiplicando
o número de cópias vendidas pelo valor unitário do
CD . Em SQL , a consulta para fazer essa operação é
escrita dessa forma :
SELECT * , ( cópias * preço_unit ) FROM rendimento
;
Em Prolog , você pode escrever esse predicado passando uma lista
de números dos argumentos , um operador aritmético , e a
consulta Prolog . O predicado cálculo executa a consulta
com o predicado call . Ele localiza os dois argumentos envolvidos
no cálculo usando o predicado arg , faz a operação
aritmética sobre os dois argumentos , e imprime o resultado .
Cada operação aritmética precisa de sua própria
cláusula e o predicado cálculo deve ser escrito da
seguinte forma :
cálculo( ( Arg1 , Op , Arg2 ) , Query ) :- call( Query ) ,
arg( Arg1 , Query , X1 ) ,
arg( Arg2 , Query , X2 ) ,
do_arith( ( X1 , Op , X2 ) , Ans ) ,
output( [X1 , X2 , Ans] ) , fail .
cálculo( _ , _ ) .
do_arith( ( X1 , + , X2 ) , Ans ) :- Ans is X1 + X2 .
do_arith( ( X1 , - , X2 ) , Ans ) :- Ans is X1 - X2 .
do_arith( ( X1 , * , X2 ) , Ans ) :- Ans is X1 * X2 .
do_arith( ( X1 , / , X2 ) , Ans ) :- Ans is X1 / X2 .
Retornar o total de rendimento com o predicado cálculo
envolve primeiro gerar a consulta com o predicado from , convertendo
o nome do argumento para seu correspondente número de argumentos
, e passar o número de argumentos , o operador aritmético
, e a consulta para o predicado cálculo . O predicado aritmética
manipula essas operações :
aritmética( ( Arg1 , Op , Arg2 ) , Functor ) :- from( Functor
, Table , Query ) ,
nth_arg( Arg1 , Table , Argnum1 ) ,
nth_arg( Arg2 , Table , Argnum2 ) ,
cálculo( ( Argnum1 , Op , Argnum2 ) , Query ) .
Quando você chama o predicado aritmética da seguinte forma
:
? - aritmética( ( cópias , * , preço_unit )
, rendimento ) .
O resultado será a seguinte tabela :
700.000 20 14.000.000
650.000 15 9.750.000
A função COUNT
A função COUNT determina quantas instâncias
de uma coluna estão presentes numa tabela . Por exemplo , a consulta
SQL conta o número de músicas do CD ‘ Never Mind ’
.
Em Prolog , você pode escrever o predicado para incrementar um
contador cada vez que um objetivo é encontrado . O predicado count
, usa o predicado from para gerar a consulta e ctr_set para
inicializar o contador . O predicado counter chama a consulta e
incrementa o contador toda vez que a consulta sucede . Quando counter
termina , o número é retornado através do predicado
ctr_is .
count( Functor , Arg1 , ( Arg2 , Op , Val ) , Count ) :- from( Functor
, Table , Query ) ,
nth_arg( Arg2 , Table , Num ) ,
ctr_set( 0 , 0 ) , ! ,
counter( ( Num , Op , Val ) , Query ) ,
ctr_is( 0 , Count ) .
counter( ( Num , Op , Val ) , Query ) :- call ( Query ) ,
arg( Num , Query , X ) ,
test( X , Op , Val ) ,
ctr_inc( 0 , _ ) , fail .
counter( _ , _ ) .
Quando chamado com os seguintes argumentos , o predicado retorna a variável
X instanciada com o número de ocorrências do procurado
.
? - count( cd_música , música , ( título , =
= , ‘ Never Mind ’ ) , X ) .
X = 6
A função SUM
A função SUM calcula a soma de todos os valores
contidos numa coluna . Por exemplo , o número total de cópias
vendidas de todos os CD’s pode ser calculado com a seguinte consulta SQL
:
Em Prolog , você deve escrever um predicado para armazenar o
total ocorrido no banco . Inicialmente , o predicado select_sum
limpa a chave para ter certeza que nenhuma soma anterior esteja presente
no banco . Então , usa o predicado from e nth_arg
para gerar a consulta Prolog e determinar qual coluna somar .
select_sum( Functor , Arg , Sum ) :- eraseall( sum ) ,
from( Functor , Table , Query ) ,
nth_arg( Arg , Table , N ) ,
do_sum( Query , N ) ,
recorded( sum , Sum , _ ) .
O predicado do_sum executa a consulta , localiza o argumento
a ser adicionado a soma , chama o predicado para fazer a operação
de soma atual , e então falha para executar a consulta de novo .
do_sum( Query , N ) :- call( Query ) , arg( N , Query , X ) , sum(
X ) , fail . do_sum( _ , _ ) .
Duas cláusulas manipulam a operação soma . A primeira
cláusula recupera a soma corrente do banco de dados , adiciona o
próximo valor à soma , e troca soma anterior com a nova soma
. A segunda cláusula manipula o caso de nenhuma soma estar presente
no banco de dados .
sum( Sum ) :- recorded( sum , X , Ref ) ,
X1 is X + Sum ,
replace( Ref , X1 ) , ! .
sum( Sum ) :- recorda( sum , Sum , _ ) .
Select_sum retorna o número total de CD’s vendidos quando
chamado com os seguintes argumentos :
select_sum( rendimento , cópias , X ) .
X = 1.350.000
Usando Listas para coletar os resultados
Algumas operações SQL podem ser implemetadas coletando
os resultados em uma lista . Duas operações que caem nessa
categoria são as funções DISTINCT e ORDER
BY .
A função DISTINCT
DISTINCT retorna somente uma ocorrência de uma entrada
repetida no banco de dados . Por exemplo , quando retornamos os títulos
dos CD’s acessando a tabela cd_música usando DISTINC
, somente uma instância de cada nome de CD será retornado
.
A consulta para retornar a coleção de títulos
da tabela cd_música irá gerar uma lista de títulos
, adicionando um título a lista se este não for membro da
lista . Com a consulta gerada pelo predicado from e o número de
argumentos dos argumentos distintos retornado pelo predicado nth_arg
, o predicado distinct chama a consulta e então checa se
contém valores de argumentos distintos .
select_distinct( Arg , Functor , List ) :- eraseall( distinct ) ,
from( Functor , Table , Query ) ,
nth_arg( Arg , Table , N ) ,
distinct( N , Query ) ,
recorded( distinct , List , _ ) .
distinct( N , Query ) :- call( Query ) ,
is_distinct( N , Query ) , fail .
distinct( _ , _ ) .
Três cláusulas is_distinct manipulam a inserção
ou não de um valor à lista . A primeira cláusula sucede
quando o valor é membro da lista . Então é encontrada
a próxima instância da consulta no banco . Se o valor não
é membro da lista , a segunda cláusula sucede , adicionando
o valor à lista e substituindo a lista anterior com a nova lista
. A terceira cláusula sucede quando não há nenhuma
lista distinct no banco de dados , então adiciona as novas instâncias
à lista .
is_distinct( N , Query ) :- arg( N , Query , X ) ,
recorded( distinct , List , _ ) ,
member( X , List ) , ! .
is_distinct( N , Query ) :- arg( N , Query , X ) ,
recorded( distinct , List , Ref ) ,
append( List , [X] , NewList ) ,
replace( Ref , NewList ) , ! .
is_distinct( N , Query ) :- arg( N , Query , X ) ,
recorda( distinct , [X] , _ ) .
Select_distinct pode ser chamado com os seguintes argumentos
para retornar a lista de títulos contidos na tabela cd_música
:
? - select_distinct( título , cd_música , List ) .
List = [‘ Ten ’ , ‘ Never Mind ’] .
A função ORDER BY
A vezes os dados não estão armazenados da forma que o
usuário deseja . Prolog , por exemplo , armazena as informações
na ordem que elas são adicionadas . Em algum momento , o usuário
pode deseja ordenar as informações por uma coluna . Esse
procedimento é feito pela função ORDER BY que
coleta o resultado de uma consulta em uma lista e ordena essa lista . Essa
consulta SQL ordena uma lista de nomes dos músicos em ordem alfabética
:
Um predicado para ordenar uma lista de valores pode ser implementado
usando o mesmo procedimento de select_distinct , com algumas pequenas
diferenças . O predicado order_by não tem que retirar
valores duplicados e deve ordenar a lista . Como select_distinct
, order by mantém a lista no banco de dados . A consulta
é gerada pelo predicado from e os argumentos da lista a ordenar
são encontrados com o predicado nth_arg . Collect_all
chama a consulta e localiza o argumento a ser adicionado à lista
. Add_to recupera a lista do banco de dados e adiciona o novo valor
à lista . Ele não checa duplicados . Depois que o valor é
adicionado à lista , collect_all falha para encontrar a próxima
linha na tabela . Depois que todos os valores foram encontrados , o predicado
order_by ordena a lista final e retorna a lista ordenada para o
argumento NewList .
order_by( Arg , Functor , NewList ) :- eraseall( orderby ) ,
from( Functor , Table , Query ) ,
nth_arg( Arg , Table , N ) ,
collect_all( N ,Query ) ,
recorded( orderby , List , _ ) ,
sort( List , NewList ) .
collect_all( N , Query ) :- call( Query ) ,
arg( N , Query , X ) ,
add_to( X , List ) , fail .
collect_all( _ , _ ) .
add_to( X , List ) :- recorded( orderby , List , Ref ) ,
append( List , [X] , NewList ) ,
replace( Ref , NewList ) , ! .
add_to( X , List ) :- recorda( orderby , NewList , _ ) .
Muitas implementações Prolog já provém
o predicado sort . Mas aqui estão dois pequenos predicados
com o algoritmo de sort - o bubble sort e o insert sort
.
bubble( L1 , L2 ) :- append( U , [A , B|V] , L1 ) ,
B @< A ,
append( U , [B , A|V] , M ) ,
bubble( M , L2 ) .
bubble( L1 , L1 ) .
insort( [H|T] , S ) :- insort( T , L ) ,
insort( [ ] , [ ] ) .
insert( X , [H|T] , [H|L] ) :- H @< X , ! ,
insert( X , L , [H|L] ) .
Agora , quando chamamos com os seguintes argumentos :
? - order_by( nome , músico_banda , X ) .
Order_by instancia X com a lista :
X = [Chris Novoselic , David Grohl , Eddie Vedder , Jack Irons ,
Jeff Ament , Kurt Cobain , Mike McCready , Stone Gossard]
Os predicados between e order_by definidos aqui têm
seu uso limitado porque manipulam somente colunas simples das tabelas .
Pode-se usar um método alternativo para coletar os resultados de
uma consulta . O grupo de predicados disponíveis - setof
, bagof , findall - podem ser usados para implementar as
funções DISTINCT e ORDER BY . Esses predicados
coletam os resultados de uma consulta numa lista Prolog , e diferem na
forma como mostram os resultado , removendo duplicados ou ordenando-os
.
Acessando mais de uma tabela ( Joins )
Até então , as consultas realizadas só acessavam
uma tabela de cada vez . Em SQL , é possível combinar informações
de mais de uma tabela . Consultas que acessam mais de uma tabela são
chamadas de joins . Por exemplo , retornar o título , banda
e músicas de um CD no banco de dados requer a junção
das tabelas cd e cd_música , como mostrado na fig.
7. A junção é feita através da coluna título
pois ambas as tabelas compartilham as mesmas informações
contidas nessa coluna .

Fig. 7 - Junção de duas tabelas .
SQL não requer que as colunas que efetivam a junção
tenham o mesmo nome . De fato , todas as colunas têm um nome único
. Em SQL , o nome completo de qualquer coluna consiste no nome da tabela
seguindo de ponto , seguindo do nome da coluna . O nome completo de uma
coluna não é necessário em consultas envolvendo uma
só tabela . O sistema pode assumir que essas colunas têm o
mesmo prefixo de nome da tabela . Mas quando tabelas são unidas
, os nomes das colunas se tornam ambíguos , por isso , a declaração
SELECT que une duas tabelas deve receber o nome completo das colunas
. SQL pode unir tabelas de duas formas : ele pode fazer um "natural
join" ou um "outer join" . O natural join
constrói a tabela com as linhas onde o valor da coluna de junção
aparece em ambas as tabelas . O natural join se parece com uma interseção
de dois conjuntos . Um elemento é incluido na interseção
se este ocorre nos dois conjuntos . Um outer join contém
as linhas onde o valor da coluna de junção aparece em uma
ou outra tabela . O outer join se parece com uma união de
dois conjuntos . Um elemento está na união se este está
em um ou no outro conjunto . Em SQL , construindo um outer join
envolve criar uma tabela e inserir os resultados de várias consultas
na tabela .
A conjunção de objetivos em Prolog irá corretamente
encontrar o natural join das duas tabelas . Por exemplo , o natural
join das tabelas cd e cd_música será requerido
com a consulta SQL :
SELECT cd.título , cd.banda , cd_música.música
FROM cd , cd_música WHERE cd.título = cd_música.título
;
O predicado n_join gera a conjunção de objetivos
necessários para um natural join . Esse predicado aceita
nomes completos de colunas , onde o nome da tabela é separado do
nome da coluna por dois pontos . O nome completo é tratado como
um argumento único , mas o nome pode ser separado em dois valores
quando necessário . Dado o par functor:column , n_join
usa o predicado from para retornar a estrutura geral para as duas consultas
. Ele usa o predicado get_nums para encontrar o número de
argumentos para as colunas que devem se igualar nas duas consultas , e
então tenta unificar essas colunas . Se a unificação
sucede , as informações das tabelas são incluídas
na junção . O terceiro argumento é conjunção
dos dois objetivos .
n_join( Func1:Col1 , Func2:Col2 , ( Q1 , Q2 ) ) :- from( Func1 ,
Table1 , Q1 ) ,
from( Func2 , Table2 , Q2 ) ,
get_nums( Table1 , [Col1] , _ , N1 ) ,
get_nums( Table2 , [Col2] , _ , N2 ) ,
unify( Q1 , Q2 , N1 , N2 ) , ! .
unify( Q1 , Q2 , [N1| _ ] , [N2| _ ] ) :- arg( N1 , Q1 , U ) ,
A junção não deve ser baseada somente na igualdade
. Deve ser baseada também em qualquer predicado condicional . Uma
versão diferente de n_join deve ser escrito para aceitar
qualquer operador condicional . O operador é passado para o predicado
chamado do_join que faz os testes específicos . Como a segunda
versão do where , do_join usa o predicado test
para fazer a operação de comparação .
n_join( Func1:Col1 , Op , Func2:Col2 ) :- from( Func1 , Table1 ,
Q1 ) ,
from( Func2 , Table2 , Q2 ) ,
get_nums( Table1 , [Col1] , _ , Arg1 ) ,
get_nums( Table2 , [Col2] , _ , Arg2 ) ,
do_join( ( Q1 , Op , Q2 ) , Arg1 , Arg2 ) , ! .
do_join( ( Q1 , Op , Q2 ) , [Arg1] , [Arg2] ) :- call( Q1 ) , call(
Q2 ) ,
arg( Arg1 , Q1 , X ) ,
arg( Arg2 , Q2 , Y ) ,
test( X , Op , Y ) ,
format( Q1 , Q2 , L ) ,
output( L ) , fail .
do_join( _ , _ , _ ) .
format( Q1 , Q2 , L ) :- Q1 =.. [F1|T1] ,
Q2 =.. [F2|T2] ,
append( T1 , T2 , L ) .
Agora n_join pode manipular outros tipos de condições
de junção . Por exemplo , você pode adicionar informações
sobre as vendas de CD’s por região .
tabela( vendas( região , cópias ) ) .
vendas( nordeste , 200.000 ) .
vendas( sudeste , 750.000 ) .
vendas( sul , 400.000 ) .
Quando você junta essa tabela com a tabela rendimentos com a consulta
seguinte :
? - n_join( rendimentos:cópias , < , vendas:cópias
) .
n_join imprime a tabela :
Ten 700.000 20 sudeste 750.000
Never Mind 650.000 15 sudeste 750.000
Outras operações com o data dictionary
Um sistema de banco de dados flexível permite o usuário
redefinir as tabelas . Isso envolve dois problemas : atualizar o data
dictionary , pois a descrição da tabela possui nova definição
e atualizar as instâncias existentes , pois devem estar conformes
com a nova definição . Deve também permitir que o
usuário remova uma tabela que não é mais usada .
Mudando a definição de uma tabela
Em SQL , as colunas podem ser adicionadas à tabela mas não
removidas . Quando uma nova coluna é adicionada à tabela
, o valor null é colocado nessa coluna para cada instância
existente na tabela . O comando ALTER TABLE é provido por
SQL para adicionar uma nova coluna à tabela . Ele tem a forma geral
:
A descrição da coluna pode conter informação
sobre o tipo de dados que será adicionado ao data dictionary
. Vamos adicionar a coluna vendedor à tabela vendas com o comando
SQL :
Para adicionar a coluna ao data dictionary Prolog , usaremos
o predicado abaixo chamado alter_table :
alter_table( Name , Field ) :- from( Name , X , S ) ,
new_struct( X , [Field] , NewS ) ,
retract( table( X ) ) ,
assertz( table( NewS ) ) ,
alter_instances( S ) .
Primeiro , alter_table encontra a definição da
tabela , usando o predicado from . Este salva a estrutura geral
na variável S . Depois , este constrói a nova definição
da tabela contendo a nova coluna . Isso é feito com o predicado
chamado new_struct , definido abaixo :
new_struct ( S , Val , NewS ) :- S =.. List ,
append( List , Val , NewList ) ,
NewS =.. NewList .
Aqui , univ cria uma lista a partir da estrutura , adiciona
o nome da nova coluna ao final da lista , e cria de novo a nova estrutura
com o predicado univ . A velha definição da tabela
é retirada com o predicado retract e a nova estrutura é
adicionada ao banco de dados . Depois , a nova coluna deve ser adicionada
a todas as instâncias existentes no banco de dados , com o valor
null em cada instância . Dada a estrutura geral que foi criada
anteriormente , usaremos o predicado alter_instances para atualizar
o banco de dados .
alter_instances( S ) :- call( S ) ,
new_struct( S , null , NewS ) ,
retract( S ) ,
assertz( NewS ) , fail .
alter_instances( _ ) .
Para adicionar a coluna vendedor ao banco , chama-se o predicado alter_table
da seguinte forma :
? - alter_table( vendas , vendedor ) .
A coluna vendedor é adicionada à definição
da tabela e o valor null é adicionado à cada instância
no banco da dados . Por exemplo , você pode checar se a coluna foi
adicionada com a consulta select :
? - select( [região , cópias , vendedor] , vendas )
.
nordeste 200.000 null
sudeste 750.000 null
sul 400.000 null
Removendo uma tabela
Remover uma tabela envolve remover sua definição do data
dictionary e todas as instâncias da tabela do banco de dados
. Em SQL , isso é feito com o comando DROP TABLE . Em Prolog
, isso é feito encontrando a definição da tabela e
a estrutura geral com o predicado from . A definição
da tabela pode ser usada como um argumento para o predicado retract
; a estrutura geral é um argumento para o predicado eraseall
.
drop_table( Functor ) :- from( Functor , X , S ) ,
retract( table( X ) ) ,
eraseall( S ) .
Outras definições devem ser checadas antes de remover
uma tabela . Por exemplo, pode ser necessário checar se não
há nenhuma dependência entre a tabela a ser removida e outra
informação no banco . Essas dependências devem ser
armazenadas com as definições das tabelas . Outros passos
são necessários durante o processo de remoção
que checam se as dependências não existem .
Aceitando consultas SQL diretamente
Até agora estudamos as formas de transformar as consultas SQL
em predicados Prolog para poder acessar um banco de dados relacional .
Justamente porque Prolog é uma linguagem declarativa e não
imperativa como SQL . Mas outra forma de tratar as declarações
SQL pode ser usada em Prolog . Se você decidir criar um processador
de linguagem SQL , você deve reduzir a consulta à forma canônica
. A forma canônica é a forma mais geral em que uma declaração
numa linguagem pode ser expressada . Quando você determinar a forma
mais conveniente para a sua aplicação , você deverá
rescrever todos os predicados vistos até agora para aceitar essa
forma . Você deverá usar técnicas , que não
serão abordadas , de processamento de linguagem em Prolog . Essas
técnicas deverão ser usada para interpretar as declarações
SQL e convertê-las para uma forma canônica .
Referências
Dados do Trabalho
Universidade Federal do Rio de Janeiro
Curso de Bacharelado em Informática
Cadeira de Programação em Lógica
Professora : Ines de Castro Dutra
Monografia : SQL x Prolog
Aluno : Marcello Gonçalves Rego
DRE : 951307739