Universidade Federal do Rio de Janeiro
Instituto de Matemática
Curso de Informática
Cátedra Lógica em Programação
Professora: Inês
Aluno: Gustavo Faria
Paralelismo OU
Introdução
Durante anos, a computação paralela apresentava-se com uma certa aura de hermetismo, devido, principalmente, à dificuldade no desenvolvimento de programas paralelos e ao alto custo e reduzida oferta de máquinas que exploravam o paralelismo na arquitetura. Dos fabricantes dos primeiros computadores paralelos, vários não se acham mais no mercado.
Vários fatores, contudo, provocaram uma significativa mudança no quadro : a produção de processadores baratos e rápidos, a evolução das redes de computadores, o advento da computação distribuída e dos MPPs (Massively Parallel Processors). Hoje, paralelismo é sinônimo de supercomputação; mas não necessariamente de máquinas hiper-dimensionadas custando milhões de dólares.
A demanda crescente e contínua por maios poder de processamento, assim como maior capacidade de armazenamento, tem ocupado um papel central na história da computação. Uma tendência observável é que as exigências de poder computacional da parte de cientistas e engenheiros acham-se sempre um passo à frente da capacidade oferecida pela indústria.
Certas aplicações científicas agrupadas sob o nome geral de Grand Challenges são um bom exemplo disso : caracterizam-se por exigirem intenso processamento numérico e exaurirem as disponibilidades existentes de poder computacional. Como exemplos temos : simulação de materiais semicondutores, exploração de petróleo e predição do tempo. Se, por um lado, cada avanço em termos de poder computacional permite que se obtenham avanços nesses campos de pesquisa; em contrapartida, sempre se poderiam obter resultados mais confiáveis e melhores, se houvesse maior capacidade disponível: um círculo viciosos de estabelece, cada avanço gerando maiores demandas.
Simulações, por exemplo, são aplicadas em áreas vitais para o interesse científico e desenvolvimento industrial contemporâneo: monitoração de usinas nucleares, indústria automobilística e aeronáutica, predição do clima global ou dos efeitos deletérios do aquecimento do planeta, além de predições meteorológicas. Quaisquer refinamentos nos dados de entrada, ao mesmo tempo que proporcionam predições mais confiáveis e menor margem de erro, impõem uma severa carga de trabalho sobre os recursos computacionais disponíveis, levando-os ao seu limite. Já foi observado que, para se determinar os efeitos iniciais da degradação da camada de ozônio um supercomputador Cray teria de trabalhar 24 horas por dia durante 200 anos.
Tendo em mente os limites econômicos e físicos existentes quanto aos avanços possíveis na indústria microeletrônica percebe-se porque da adoção de processamento paralelo tornou-se atraente como resposta ao impulso insatisfeito por maior velocidade computacional. Afinal, não importa quão avançado ou poderoso possa ser um processador individual, se pudermos de algum modo reunir o poder de processamento de vários deles, fazendo-os cooperar na solução de uma tarefa ou problema, obteremos ainda maior velocidade e eficiência: oferece-se, assim, um meio rápido de saltar gerações de processadores sem os custos excessivos de pesquisa e desenvolvimento.
Contudo, beneficiar-se plenamente do potencial oferecido pela programação paralela requer avanços em hardware e software: proposta de novos modelos computacionais, novas linguagens de programação, novos modelos arquiteturais, além da produção de ferramentas e ambientes de programação. No que diz respeito aos modelos algorítmicos, muitas vezes não é suficiente a reestruturação dos algoritmos seqüenciais existentes, tornando-se necessário recriá-los. Mais de um método foi proposto para a paralelização de programas: compiladores inteligentes, capazes de detectar o paralelismo intrínseco do código fonte; criação de novas linguagens de programação ou extensão das linguagens existentes; inclusão de construções para troca de mensagens em linguagens de programação concorrente. O primeiro método obtém código otimizado de modo transparente ao usuário, apresentando, porém, eficiência limitada; o segundo, em troca de maior eficiência, exige a familiarização com novas linguagens ou construções; o terceiro por fim, é o método mais utilizado em vários ambientes de programação concorrente. Tanto no segundo como no terceiro método, o ônus da detecção do paralelismo recai sobre o programador, o que se apresenta certa dificuldade no início, permite mais flexibilidade e eficiência que o primeiro.
Paralelismo em Prolog
Muitos modelos de execução paralela foram desenvolvidos para ProLog. Existem basicamente dois tipo de paralelismo: o paralelismo E e o paralelismo OU. O primeiro consiste na resolução dos diversos objetivos do predicado em paralelo. No segundo, pode-se selecionar as diversas possibilidades de unificação. Entretanto, como existem diversas técnicas de exploração do paralelismo E e OU faremos uma classificação mais categórica:
Implementação de ProLog que permitem o Paralelismo:
BAP, BeBOP, Klic, Multi-BinProlog, NCL, PCN, Rolog, Densitron CS Prolog, ParaLogic, Strand-88, Muse, Andorra, Ciao, Idiom, OAPl, PEPSys, Opera, BOPLOG, Aurora, Delta-Prolog, etc.
Paralelismo OU
Como foi descrito anteriormente, o paralelismo OU surge sempre que um subojejtivo pode ser unificado com a cabeça de mais de uma cláusula, e o corpo dessas cláusulas são executadas em paralelo por diferentes agentes computacionais, que daqui para frente serão referenciados por agentes OUs.
O paralelismo OU está presente em quase todas as aplicações, embora em algumas áreas ele apareça em maior escala. Como exemplos dessas áreas citamos: parse, problemas de otimização, banco de dados.
integr(X+Y, X’+Y’) :- integr(X,X’), integr(Y,Y’)
integr(A+B, X*Y) :-
Uma consulta como integr(5*x+ln x*x, Z) é uma séria candidata para o paralelismo OU.
Deve ser ressaltado que tomando diferentes alternativas a partir de um ponto de escolha, cada agente OU estará computando uma solução diferente para a consulta original. A implementação desse princípio é relativamente simples, bastando algumas modificações na tecnologia seqüencial.
Isso só é verdade se restringirmos nossa atenção as formas mais básicas de paralelismo. Por que a implementação do paralelismo OU na sua forma mais abrangente oferece alguma complexidade.
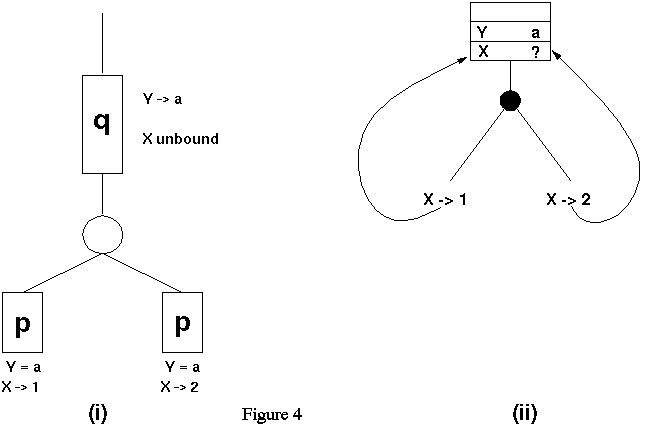
É importante salientar que a independência das alternativas exploradas pelos diferentes agentes OU existe apenas a nível teórico. Por exemplo, considere a consulta q(Y,X0, p(Y,X) e que
A árvore-OU para essa parte está em 4(i), Se por um lado a instanciação de Y com a deveria ser visível pelas duas alternativas, por outro esse processamento irá produzir diferentes associações para X. Isso introduz um problema claro que é a implementação do modelo. No processamento seqüencial apenas um ambiente será alocado para a consulta. Já com duas alternativas sendo exploradas seqüencialmente, elas podem tranqüilamente usar o mesmo ambiente.
Num sistema de paralelismo OU, as duas alternativas sendo exploradas em paralelo não podem usar o mesmo ambiente, vide 4(ii). O acesso a diversos ambientes nas alternativa paralelas cria uma dependência entre essa tarefas paralelas. Esse tipo de variável é denominada variável condicional. O problema pode ser encarado de maneiras diferentes, ou impõe restrições aos uso do paralelismo ou implementa-se um novo esquema de ambientes.
Paralelismo Ou Independente
Ele acontece quando as diferentes alternativas de um determinado ponto de escolha são independentes entre si. Isto é, nenhuma alternativa compartilha a mesma variável condicional a partir de um mesmo ponto de escolha.
A vantagem desse tipo de paralelismo é que não se torna necessário nenhum tipo de alteração no esquema de representação adotado no paradigma seqüencial.
O esforço gasto para desenvolver um sistema de exploração em paralelo é mínimo, e provê um alto nível de eficiência. Mas por outro lado, sua aplicabilidade fica um pouco limitada.
Paralelismo OU Restrito
Extende a noção do independente, permitindo o execução de alternativas que acessam variáveis condicionais irrestritas. A restrição imposta é que nenhum conflito deve ocorrer entre tais variáveis. Isso implica que as variáveis condicionais serão lidas mas não sobrepostas; ou de uma outra forma, as variáveis instanciadas por uma alternativa não será visível pelas outras(a dependência é só aparente).
A execução dessa alternativas é time-insensitive no que concerne a unificação das variáveis condicionais.
A figura 5 ilustra um exemplo de paralelismo OU restrito. Note que:
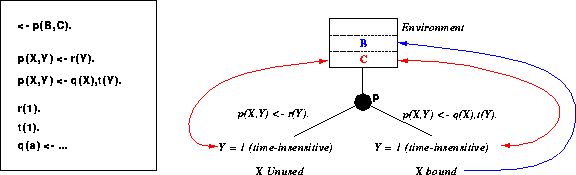
Em termos de implementação, é necessário um pouco mais do que foi preciso para o independente. A única adição relevante é a possibilidade do acesso concorrente aos mesmos objetos.
A noção desse tipo de paralelismo não foi explorado em nenhum sistema.
Paralelismo Ou Dependente
É a forma mais geral de paralelismo Ou na qual nenhuma restrição é imposta.
Essa forma mais genérica requer, como já foi dito, um desenvolvimento de um novo ambiente para solucionar o problema do acesso e unificação das variáveis condicionais.
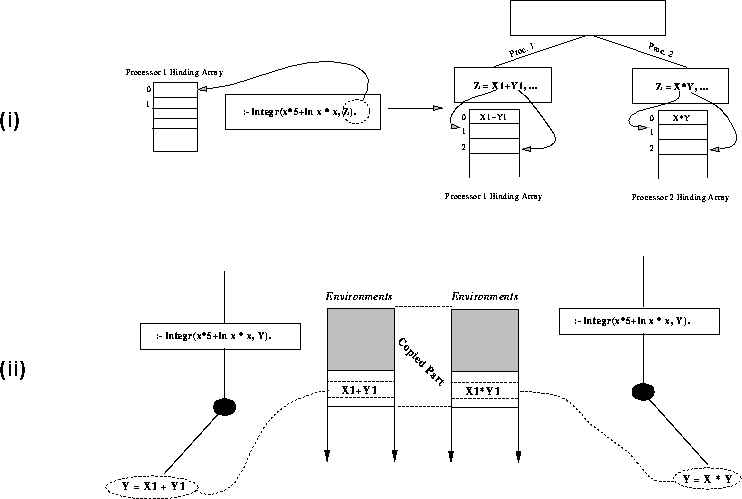
Exemplo 2.3 integr(5*x +ln x * x, Z)
O ambiente computacional deve estar organizado de tal forma que as corretas unificações aplicáveis sejam facilmente identificadas. Tal representação deve ser eficiente e sem muito overhead.
O problema foi resolvido fazendo com que cada ramo da árvore-ou tenha uma área privada, usada para armazenar as unificação das variáveis condicionais. Diverso modelos foram proposta; cerca de 20. Eles diferem pela forma que criam e acessam suas áreas privadas.
Desse modelos dois se mostraram superiores quando comparados em termos de eficiência e flexibilidade.
Overhead no Paralelismo OU
Implementa-se com pouco overhead. As duas principais implementações, Muse e Aurora, relatam um overhead acima do SICStus Prolog(base de ambas as implementações) algo entre 8% e 22% e 25%. Os resultados são encorajadores.
A maior vantagem do paralelismo OU é o fato de que ele vem de forma natural e sem muito overhead. O compilador detecta(eventualmente com a ajuda das declarações do usuário) quais são os pontos de escolha que podem ser executados em paralelo, e são definidos apropriadamente quando são criados a um custo zero, sem overhead.
O overhead varia de acordo com o modelo de paralelismo empregado. Mas ainda assim podemos fazer algumas considerações. O overhead será encontrado em algumas dessas fases:
Alguns Resultados
Alguns testes, que consistiam em comparam a diferença o tempo de resposta de uma determinada consulta variando o número de processadores, foram realizados e os resultados se encontram na tabela abaixo.
|
Número de Processadores |
Tempo |
|
1 |
3085 s |
|
4 |
1286 s |
|
8 |
563 s |
|
13 |
365 s |
|
32 |
181 s |
|
64 |
90 s |
|
128 |
103 s |
Combinando o Paralelismo Ou e o Paralelismo E
Como já foi visto no paralelismo E cada agente E processa partes diferentes de uma mesma solução de uma consulta. E no paralelismo OU cada agente OU trabalha em diferentes soluções para a mesma consulta.
Assim, se quisermos unir os benefícios de ambas as formas teremos: cada agente OU será composto por uma série de agente E.
Otimizando
Pode-se utilizar alguns recursos para otimizar o método. Como:
Conclusões
Existem alguns problemas relacionados com a implantação do paralelismo como a convivência com a forma já existentes de Prolog e a independência da arquitetura de paralelismo adotada. Mas de uma forma geral o paralelismo sai traz muitas vantagens sem desvantagens significantes. E a melhor delas: o paralelismo em Prolog sai de forma natural, não é necessário que mudar um programa já implementado no paradigma seqüencial, coisa que aconteceria em C por exemplo.
E isso me lembrou das origens do Prolog que era simular o pensamento humano. V^-se que o pensamento humano é naturalmente paralelo, naturalmente eficiente.
Bibliografia